
EasyExcel 初使用—— Java 实现读取 Excel 功能
前言
在我们项目的开发中啊,前端有时候会传送 Excel 文件给后端(Java)去解析,那我们作为后端该如何实现对 Excel 文件的解析和数据读取呢?说到这我就不得不推荐 EasyExcel 了!
EasyExcel 介绍
引用下官方对于 EasyExcel 介绍:EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。他能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
官方网址:EasyExcel官方文档 - 基于Java的Excel处理工具 | Easy Excel
快速上手 EasyExcel
前置工作
先创建一个 Spring Boot 工程,并在 pom.xml 文件添加 EasyExcel 和 Lombok 依赖。
1 | <dependency> |
知道表头
如果我们知道 Excel 数据的表头,即每列数据的类型包括有多少列时就可以用此方法读取 Excel 文件数据。
我们以下图数据为例,对改 Excel 中的数据进行获取和处理。

方法一:
首先我们创建一个名为 ExcelData 的 Java 对象,共有两个属性,分别是 date(日期列数据)和 useNum(用户列数据),每个属性对应 Excel 每列某一行中的数据。那么很显而易见,每一行的数据就是一个 ExcelData 对象,所有行的数据合起来就是一个泛型为 ExcelData 的 ExcelData 的集合。
1 | class ExcelData implements Serializable { /** * 对应表格的日期列 */ private String date; /** * 对应表格的用户数列 */ private Integer userNum; } |
随后编写一个测试类,并在其中编写测试方法。
EasyExcel 的 read 方法有很多中构造方法,其中 Class head 就是表头类型,传入它还要传入 ReadListener 监听器,以便在去读取每行数据时做些自定义操作。我们直接传入它的实现类实例,因为 PageReadListener 支持逐页读取数据,通过读取指定行数的数据保证占用更少的内存。
话不多说直接上代码:
1 | /** * 知道表头,并形成映射关系 */ public void doImportsForMapping() throws FileNotFoundException{ // 读取 resource 目录下的 Excel 文件(网站数据.xlsx) File file = ResourceUtils.getFile("classpath:网站数据.xlsx"); // 创建一个 list 存储每行的数据,即 ExcelData 对象 List<ExcelData> list = new ArrayList<>(); // 直接使用 EasyExcel 的 read 方法,同时定义表头的类型,以便将列中数据映射为 ExcelData 对象 EasyExcel.read(file, ExcelData.class, new PageReadListener<ExcelData>(dataList -> { // 并且每行数据,并将其 add 至 list 中 for (ExcelData excelData : dataList) { if (excelData != null) { list.add(excelData); } } })).excelType(ExcelTypeEnum.XLSX).sheet().doRead(); // 指定 Excel 的文件后缀,开始分析读取 for (ExcelData excelData : list) { System.out.println(excelData.getDate() + "," + excelData.getUserNum()); } } |
执行结果:

方法二:
方法一是直接一次性读取 Excel 中的数据,缺少要读取的数据行数和一些自定义操作,所以我们在这里对上面的代码增强一下。
在此方法中我们通过匿名内部类的方式实现 ReadListenser 接口,无需额外写一个类去实现 ReadListener了。我们设置了一个临时存储的列表(大小为 2),当每次读取的数据(执行 invoke 方法)添加到临时存储表中。当其长度超过 2 时进行全部删除,在删除前我们可以将临时存储的列表存到数据库中,或进行一些其他的自定义操作。
doAfterAllAnalysed 方法是分析并获取所有的数据后会执行的一个方法,我们可以在其中打上日志,表示 Excel 所有数据已存入数据库中。
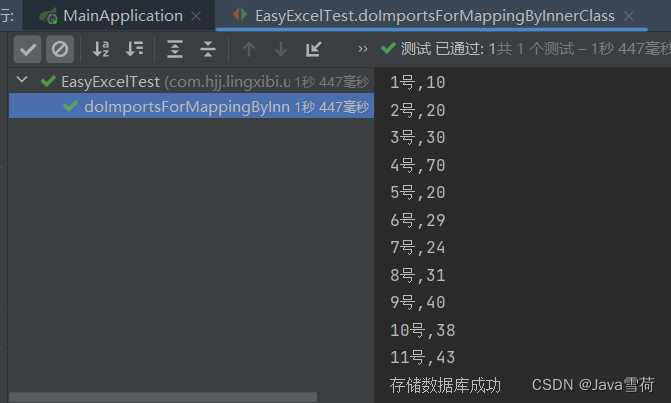
1 | /** * 知道表头,并形成映射关系 * @throws FileNotFoundException */ public void doImportsForMappingByInnerClass() throws FileNotFoundException{ File file = ResourceUtils.getFile("classpath:网站数据.xlsx"); EasyExcel.read(file, ExcelData.class, new ReadListener<ExcelData>() { // 单次缓存的数据量 public static final int BATCH_COUNT = 2; // 临时存储的列表 private List<ExcelData> cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT); @Override public void invoke(ExcelData excelData, AnalysisContext analysisContext) { cachedDataList.add(excelData); getData(excelData); if (cachedDataList.size() >= BATCH_COUNT) { cachedDataList = ListUtils.newArrayListWithExpectedSize(BATCH_COUNT); } } @Override public void doAfterAllAnalysed(AnalysisContext analysisContext) { System.out.println("存储数据库成功"); } private void getData(ExcelData excelData) { System.out.println(excelData.getDate() + "," + excelData.getUserNum()); } }).excelType(ExcelTypeEnum.XLSX).sheet().doRead(); } |
执行结果:
不知道表头
方法三:
上面的两种方法都是我们知道表头,包括列的类型和列数量的情况下对 Excel 文件进行数据获取的。那我们不知道表头信息,又该如何操作呢?
我们依赖利用 EasyExcel 的 read 方法,和前面的步骤大差不差,只不过这次参数少了,如果你还要获取表头即表格的第一行数据,还可通过 headRowNumber 方法指定首行编号为 0。
此时返回的是一个 List<Map<Integer, String>> 集合,其中 Map 的 键对应表格的列编号(从 0 开始),值就是对应某一行某一列的值,List 的索引代表某一行的数据。调用 Map 对象的 values() 方法即可直接获取某一行数据的集合,List<Map<Integer, String>> 就是所有行数据的集合。我们这说可能不太直观,我把它打印出来给你们看就很简单明了了。
1 | [{0=日期, 1=用户数}, {0=1号, 1=10}, {0=2号, 1=20}, {0=3号, 1=30}, {0=4号, 1=70}, {0=5号, 1=20}, {0=6号, 1=29}, {0=7号, 1=24}, {0=8号, 1=31}, {0=9号, 1=40}, {0=10号, 1=38}, {0=11号, 1=43}] |
代码如下:
1 | public void doImport() throws FileNotFoundException { List<Map<Integer, String>> list = null; File file = ResourceUtils.getFile("classpath:网站数据.xlsx"); try { list = EasyExcel.read(file) .excelType(ExcelTypeEnum.XLSX) .sheet() .headRowNumber(0) .doReadSync(); } catch (Exception e) { throw new RuntimeException("读取 Excel 文件失败"); } StringBuilder stringBuilder = new StringBuilder(); for (int i=0;i<list.size();i++) { // 转为 LinkedHashMap 主要是为了保证读取的数据和表格顺序一致 LinkedHashMap<Integer, String> linkedHashMap = (LinkedHashMap) list.get(i); List<String> dataList = linkedHashMap.values().stream() .filter(ObjectUtils::isNotEmpty).collect(Collectors.toList()); stringBuilder.append(StringUtils.join(dataList, ",")).append("\n"); } System.out.println(stringBuilder.toString()); } |
执行结果:

总结
如果知道表头并且数据量较小,就用方法一,如果数据量较大或者想添加一些自定操作就用方法二。如果不知道表头并且想要读取表头的信息就用方法三。

