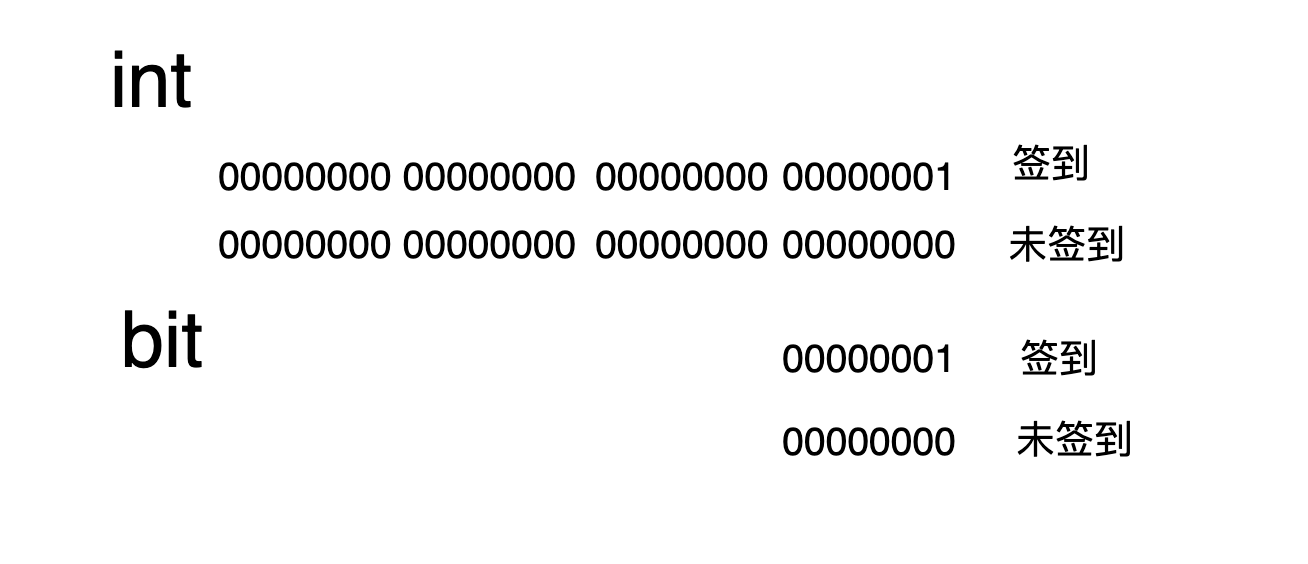面试狗 - interviewdog 项目笔记 前端初始化配置 Next.js 有两种开发模式(App Router / Page Router),注意,本项目用的是新的开发模式 App Router,建议看英文官方文档:https://nextjs.org/docs/getting-started/installation#automatic-installation
执行安装命令:
1 npx create-next-app@latest
历史 next-app 版本:https://www.npmjs.com/package/next?activeTab=versions
安装 prettier (代码自动格式化插件),安装命令
1 npm install --save-dev --save-exact prettier
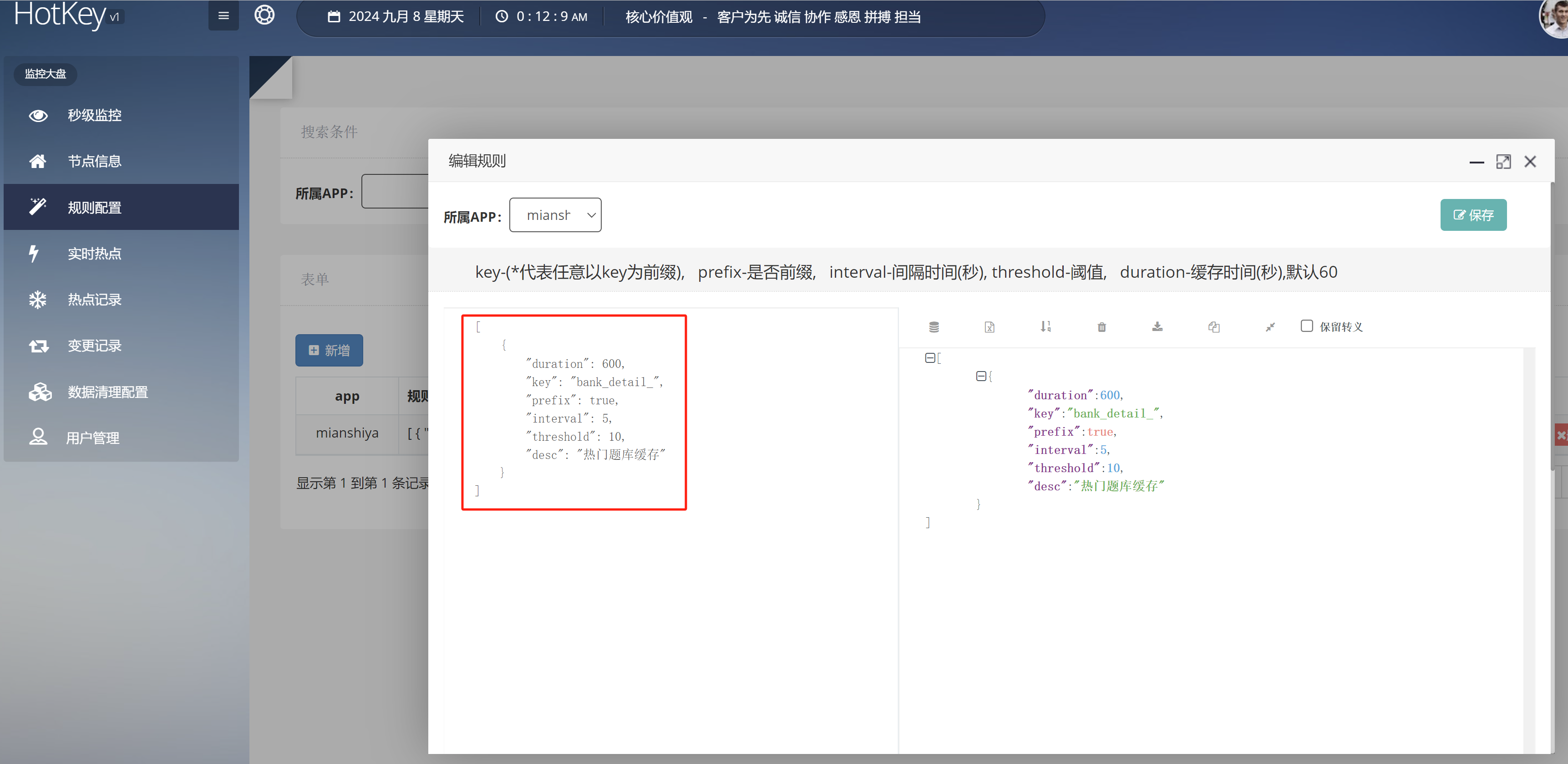
修改 .eslintrc.json 文件可以改变校验规则,一般自己做项目不需要修改。
1 2 3 { "extends": ["next/core-web-vitals", "prettier"] }
如果报错 Error: Failed to load config “prettier” to extend from. Referenced from: D:\projects\interviewdog-frontend.eslintrc.json 则执行以下命令:
1 npm i eslint prettier-eslint eslint-config-prettier --save-dev
安装 antd 组件库
针对 App Router 模式的 Next.js,需要处理页面闪动情况
1 npm install @ant-design/nextjs-registry --save
修改页面全局布局文件 app/layout.tsx
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import "./globals.css" ;import {AntdRegistry } from '@ant-design/nextjs-registry' ;export default function RootLayout ({ children, }: Readonly<{ children: React.ReactNode; }> ) { return ( <html lang ="en" > <body > <AntdRegistry > {children}</AntdRegistry > </body > </html > ); }
如果能在 page.tsx 文件中引入组件,则代表组件库安装成功
1 <Button type="primary">Primary Button</Button>
安装 Ant Design 高级组件:https://procomponents.ant.design/components/layout?tab=api#packages-layout-src-components-layout-tab-api-demo-base
1 npm i @ant-design/pro-components --save
注意,引入 Ant Design 后,不建议引入 Tailwind CSS 了,可能会有样式冲突
Next.js 开发规范 1、约定式路由 Next.js 使用 约定式路由,根据文件夹的结构和名称,自动将对应的 URL 地址映射到页面文件。
常见的几种路由规则如下: 1)基础规则:以 app 目录作为根路径,根据文件夹的名称和嵌套层级,自动映射为 URL 地址。注意,只有目录下直接包含 page 文件(js、jsx、ts、tsx都支持),才会被识别为路由。
2)路由组:可以通过(xxx)语法,创建一个路由组,不会被转化为路径,可用于对路由进行分组管理,比如同组路由使用同一套布局。
3)动态路由:可以通过[xxx]语法,让多个不同参数的 URL 复用同一个页面,比如app/question/[questionId]/page.tsx 中 questionld 就是动态路由参数,可以匹配 /question/1、/question/2 等URL地址,在页面中可以获取到 questionld 并加载不同的题目。
1 2 3 export default function Page ({ params }: { params: { questionId: string } } ) { return <div > 我的题目: {params.questionId}</div > }
以上只是 Next.js 的几种常用路由规则,还有其他的规则,详情可以见 Next.js 的官方文档:https://nextjs.org/docs/app/building-your-application/routing
2、静态资源 Next.js 约定 在 /public 目录下存放静态资源。在其中新建 assets 目录,可以在其中存放图片等静态资源文件,比如网站 logo
对应官方文档:https://nextjs.org/docs/app/building-your-application/optimizing/static-assets
接着可以使用 Next.js 的 Image 组件加载静态资源,比如:
1 <Image src={`/assets/logo.png`} alt={alt} width="64" height="64" />
注意,某些特殊的、常用的元信息文件不是放在 public 目录下,而是应该根据特定规则放在 app 目录下!对应官方文档:https://nextjs.org/docs/app/api-reference/file-conventions/metadata比如将 favicon.ico 放到 app 的根目录下,可展示站点小图标:
3、文件组织形式 首先,项目中的每个页面和组件都是单独的文件夹。
基于 Nextjs 的约定式路由,我们每个页面目录内需要添加 page.tsx页面文件和 index.css 样式文件;每个组件目录内添加 index.tsx页面文件和index.css 样式文件。
对于项目中多页面公用的组件,放在src/components目录下;对于某个页面私有的组件,放在该页面的components 目录下
4、页面开发规范 Next.js 支持 React 的语法,可以用函数的方式声明页面和组件。每个页面的根元素必须有 id、每个组件根元素必须有 className,用于控制样式和快速定位。
1)**为了区分服务端和客户端渲染,每个页面(或组件)都必须在开头显示编写use client或use server**比如定义一个客户端渲染的页面,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 "use client" ;import "./index.css" ;export default function HomePage ( return ( <main id ="homePage" > <div > 程序员鱼皮x编程导航的项目教程 </div > </main > ); }
2)定义组件时,需要使用 ts 声明组件属性的类型,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 "use client" ;import { Viewer } from "@bytemd/react" ;import "./index.css" ;interface Props { value?: string ; } const MdViewer = (props: Props ) => { const { value = "" } = props; return ( <div className ="md-viewer" > <Viewer value ={value} plugins ={plugins} /> </div > ); }; export default MdViewer ;
5、其他注意事项 1)开发时要严格注意 TypeScript 的类型和编辑器的错误提示,并且定期打包构建。因为 Next.js 的构建要求非常严格,稍有不慎就会报错。构建报错的话,注意查看和处理构建中的报错信息。
2)在项目中慎用 window 等浏览器环境才支持的对象,服务端无法使用。注意保证客户端渲染页面和服务端渲染页面的一致性,否则会出现水合错误。
前端万能模板开发
Next.js 的页面名称要为 page.tsx,React 则为 index.tsx
全局通用布局 先创建 layouts 布局目录,创建一个基础布局,并将基础布局组件包裹 layout.tsx 文件的 children 属性
layout.tsx:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import "./globals.css" ;import {AntdRegistry } from '@ant-design/nextjs-registry' ;import BasicLayout from "@/layouts/BasicLayout" ;import React from "react" ;export default function RootLayout ({ children, }: Readonly<{ children: React.ReactNode; }> ) { return ( <html lang ="en" > <body > <AntdRegistry > <BasicLayout > {children} </BasicLayout > </AntdRegistry > </body > </html > ); }
src/layouts/BasicLayout/index.tsx:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 "use client" ;import {GithubFilled , LogoutOutlined , PlusCircleFilled , SearchOutlined ,} from '@ant-design/icons' ;import {ProLayout ,} from '@ant-design/pro-components' ;import {Dropdown , Input ,} from 'antd' ;import React from 'react' ;import Image from "next/image" ;import {usePathname} from "next/navigation" ;import Link from "next/link" ;import GlobalFooter from "@/components/GlobalFooter" ;import {menus} from "../../../config/menu" ;const SearchInput = ( return ( <div key ="SearchOutlined" aria-hidden style ={{ display: 'flex ', alignItems: 'center ', marginInlineEnd: 24 , }} onMouseDown ={(e) => { e.stopPropagation(); e.preventDefault(); }} > <Input style ={{ borderRadius: 4 , marginInlineEnd: 12 , }} prefix ={ <SearchOutlined /> } placeholder="搜索题目" variant="borderless" /> </div > ); }; interface Props { children : React .ReactNode } export default function BasicLayout ({children}: Props ) { const pathname = usePathname (); return ( <div id ="basicLayout" style ={{ height: '100vh ', overflow: 'auto ', }} > <ProLayout title ="面试狗" logo ={ <Image src ="/assets/logo.png" height ={32} width ={32} alt ="面试狗" /> } layout="top" location={{ pathname, }} avatarProps={{ src: 'https://gw.alipayobjects.com/zos/antfincdn/efFD%24IOql2/weixintupian_20170331104822.jpg', size: 'small', title: 'C1own', render: (props, dom) => { return ( <Dropdown menu ={{ items: [ { key: 'logout ', icon: <LogoutOutlined /> , label: '退出登录', }, ], }} > {dom} </Dropdown > ); }, }} actionsRender={(props) => { if (props.isMobile) return []; return [ <SearchInput key ="searchInput" /> , <a href ="https://www.github.com/dnwwdwd" target ="_blank" key ="github" > <GithubFilled key ="GithubFilled" /> , </a > ]; }} headerTitleRender={(logo, title, _) => { const defaultDom = ( <a > {logo} {title} </a > ); if (typeof window === 'undefined') return defaultDom; if (document.body.clientWidth < 1400) { return defaultDom; } if (_.isMobile) return defaultDom; return ( <> {defaultDom} </> ); }} // 渲染底部栏 footerRender={(props) => { return <GlobalFooter /> ; }} onMenuHeaderClick={(e) => console.log(e)} menuDataRender={() => { return menus; }} menuItemRender={(item, dom) => ( <Link href ={item.path || '/'} target ={item.target} > {dom} </Link > )} > {children} </ProLayout > </div> ); };
其中 {children} 替换了原来的 PageContainer 组件,这样不同的页面就可以复用公共的布局,同时不同的页面能显示不同的内容
1.在 prolayout 组件中配置 logo 和 title 属性可以修改导航栏 logo 和标题,将当前页面的 pathname 传给 location 属性时,这个 procomponents 组件库会自动渲染菜单项
另外在菜单项 item 可以通过添加 hideInMenu: true 来控制菜单项是否显示
2.在服务端渲染中获取 pathname 可通过 next.js 的 usePathname 实现
3.通过 menuDataRender 定义有哪些菜单项
1 2 3 4 5 6 7 8 9 10 11 12 menuDataRender={() => { return [ { path : 'questions' , name : '题目' }, { path : 'banks' , name : '题库' }, ] }}
4.根据 menuItemRender 指定点击菜单项的动作
1 2 3 4 5 6 7 menuItemRender={(item, dom ) => ( <Link href ={item.path || '/'} target ={item.target} > {dom} </Link > )}
5.通过 footerRender 可以渲染底部栏,我们可以自己定义一个底部栏并引入它
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 footerRender ={(props ) => { return <GlobalFooter /> }} import React from 'react' ;import './index.css' ;export default function GlobalFooter ( const currentYear = new Date ().getFullYear (); return ( <div className ="global-footer" > <div > @ {currentYear} AI 刷题平台</div > <a href ="https://www.github.com/dnwwdwd" target ="_blank" > 作者:C1own </a > </div > ); };
6.注意使用客户端渲染时,请删除关于 windows、useState document 相关的代码!!!
安装请求库 1、安装 axios 库
2、全局定义请求
在这个文件中可以配置全局响应拦截器和超时时间,是否携带 cookie 等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import axios from "axios" ;const myAxios = axios.create ({ baseURL : "http://localhost:8101" , timeout : 10000 , withCredentials : true , }); myAxios.interceptors .request .use ( function (config ) { return config; }, function (error ) { return Promise .reject (error); }, ); myAxios.interceptors .response .use ( function (response ) { const { data } = response; if (data.code === 40100 ) { if ( !response.request .responseURL .includes ("user/get/login" ) && !window .location .pathname .includes ("/user/login" ) ) { window .location .href = `/user/login?redirect=${window .location.href} ` ; } } else if (data.code !== 0 ) { throw new Error (data.message ?? "服务器错误" ); } return data; }, function (error ) { return Promise .reject (error); }, ); export default myAxios;
3、自动生成请求代码
安装自动生成请求接口代码库:
1 npm i --save-dev @umijs/openapi
在 项目根目录 新建openapi.config.ts ,根据自己的需要定制生成的代码:
1 2 3 4 5 6 7 const { generateService } = require ("@umijs/openapi" );generateService ({ requestLibPath : "import request from '@/libs/request'" , schemaPath : "http://localhost:8101/api/v2/api-docs" , serversPath : "./src" , });
4、执行生成代码的命令
在 package.json 文件中添加如下脚本
1 "openapi" : "ts-node openapi.config.ts"
如果执行如上命令出现 ts-node 不是内部或外部命令则 执行这个命令 npm install --save-dev ts-node
全局状态管理 1、什么是全局状态管理?
是指多个页面需要共享或者跟踪变化的变量,可以放到全局来统一维护,而不是每个页面分别维护和获取。适合作为全局状态的数据:记登录用户信息(每个页面几乎都要用)
在 Vue 中,主流的状态管理库有 Vuex 和 Pinia;在 React 项目中,主流的状态管理库是 Redux,本项目也将使用它。
2、Redux 基本概念
React Redux 官方文档:https://react-redux.js.org/Redux 中有一些常用的核心概念,不用理解,简单了解一下即可。 1)Store:整个应用状态(state)的容器,负责存储应用的状态,并提供访问状态、派发(dispatch)动作以及注册监听器等功能。 2)Action:一个普通的 JavaScript 对象,描述了状态变化的意图。每个 action 必须包含一个 type 字段表示动作类型。 一般开发中,我们会用一个字符串常量(Action Types)来标识不同的动作类型。比如改变计数器需要的 increment或 decrement:
1 2 const INCREMENT = 'INCREMENT' ;const DECREMENT = 'DECREMENT' ;
还会用 Action Creators 动作创建器函数来生成 action 对象,比如:
1 2 3 4 5 6 7 const increment = ( type : INCREMENT , }); const decrement = ( type : DECREMENT , });
3)Dispatch:用于发送 action,触发状态更新
4)Reducer:俗称状态处理器,根据当前状态和传入的 action 返回新的状态的函数。比如:
1 2 3 4 5 6 7 8 9 10 11 12 const initialState = { count: 0 }; function counterReducer(state = initialState, action) { switch (action.type) { case INCREMENT: return { ...state, count: state.count + 1 }; case DECREMENT: return { ...state, count: state.count - 1 }; default: return state; } }
3、状态管理实战
React Redux 官方入门文档:https://react-redux,js.org/tutorials/quick-start
由于我们使用的是 TypeScript,还要参考 TypeScript 的快速启动文档:https://react-redux.js.org/tutorials/typescriptquick-start 。对于新手,上面两个文档最好按顺序阅读。
其实以前 Redux 的使用成本还是稍微有点高的,但官方提供了 Redux Toolkit,可以简化使用 Redux 的开发。 1)安装
1 npm install @reduxjs/toolkit react-redux
2)配置 store
Store 是整个应用状态(state)的容器,负责存储应用的状态,并提供访问状态、派发(dispatch)动作以及注册监听器等功能。 在项目的 src 目录下新建 stores目录,用于存放所有的状态。然后在 stores目录下新建 index.ts 文件,创建一个空的 Redux Store:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import {configureStore} from "@reduxjs/toolkit" ;import loginUser from "@/stores/loginUser" ;const store = configureStore ({ reducer : { loginUser, }, }); export type RootState = ReturnType <typeof store.getState >export type AppDispatch = typeof store.dispatch export default store;
3)在项目中引入 Redux Store,修改 app/layout.tsx 项目全局入口文件即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import store from '@/stores' import { Provider } from 'react-redux' export default function RootLayout ({ children, }: Readonly<{ children: React.ReactNode; }> ) { return ( <html lang ="en" > <body > <AntdRegistry > <Provider store ={store} > <BasicLayout > {children}</BasicLayout > </Provider > </AntdRegistry > </body > </html > ); }
4)定义 Slice
Slice 是 Redux Toolkit 中的概念,它将状态和相关的 reducer 逻辑组织在一起,便于模块化管理。每个 sice 通常代表应用中的一部分状态(如用户、产品、购物车等)。
在没有 Redux Toolkit 和 Slice 之前,传统的 Redux 开发需要定义 action types、action creators 和 reducer 函数,所有这些通常需要在不同的文件中编写,增加了代码的复杂性和维护成本。
在 stores 目录下新建 loginUser.ts ,创建一个 slice 用于存储当前登录用户的信息。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import { createSlice, PayloadAction } from "@reduxjs/toolkit"; import { RootState } from "@/stores/index"; // 默认用户 const DEFAULT_USER: API.LoginUserVO = { userName: "未登录", userProfile: "暂无简介", userAvatar: "/assets/notLoginUser.png", userRole: "guest", }; /** * 登录用户全局状态 */ export const loginUserSlice = createSlice({ name: "loginUser", initialState: DEFAULT_USER, reducers: { setLoginUser: (state, action: PayloadAction<API.LoginUserVO>) => { return { ...action.payload, }; }, }, }); // 修改状态 export const { setLoginUser } = loginUserSlice.actions; export default loginUserSlice.reducer;
注意:全局状态信息只能在客户端组件获取
5)在 Store 中引入新创建的 Slice,写在 reducer 里:
1 2 3 4 5 6 7 import loginUser from "./loginUser" ;const store = configureStore ({ reducer : { loginUser, }, });
6)获取状态 注意,状态是维护在客户端的,可以在任意 客户端渲染 页面(或组件)中使用状态,服务端渲染无法使用。 使用下列语法获取状态:
1 const loginUser = useSelector ((state: RootState ) => state.loginUser );
7)修改状态
修改状态也很方便,可以在 首次进入页面时,尝试获取登录用户信息。修改 app/layout.tsx 的全局初始化逻辑,编写远程获取登录用户数据的代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 const InitLayout : React .FC < Readonly <{ children : React .ReactNode ; }> > = ({ children } ) => { const dispatch = useDispatch<AppDispatch >(); const doInitLoginUser = useCallback (async () => { const res = await getLoginUserUsingGet (); if (res.data ) { dispatch (setLoginUser (res.data )); } else { setTimeout (() => { const testUser = { userName : "测试登录" , id : 1 }; dispatch (setLoginUser (testUser)); }, 3000 ); } }, []); useEffect (() => { doInitLoginUser (); }, []); return <> {children}</> };
其中,通过 dispatch 触发全局状态的更新:
1 2 3 4 const dispatch = useDispatch<AppDispatch >();dispatch (setLoginUser ({...}));
扩展
有些页面可以不用获取全局初始化状态,比如用户登录和用户注册页,可以根据 pathname 判断:
1 2 3 4 5 6 7 8 9 10 const pathname = usePathname ();if ( !pathname.startsWith ("/user/login" ) && !pathname.startsWith ("/user/register" ) ) { ... }
全局权限管理 需求:能够灵活配置每个页面所需要的用户权限,由全局权限管理系统自动校验和拦截,而不需要在每个页面中编写权限校验代码,提高开发效率。 还要能够根据权限控制导航菜单的显隐,只有具有权限的菜单,才对用户可见。
实现方案 1.在路由配置文件,定义某个路由的访问权限。由于 Next.js 项目是约定式路由,只有我们自定义的菜单配置文件,可以在菜单配置文件中定义权限。
2.每次访问页面时,根据用户要访问页面的路由权限信息,判断用户是否有对应的访问权限,并进行相应的拦截处理。这是一个全局逻辑,可以在项目根布局app/layout.tsx中添加。
3.导航栏展示菜单时,可以过滤掉登录用户没有权限的菜单项,从而实现根据权限控制导航菜单的显隐
开发实现 1)在 app 目录下新建 forbidden 无权限页面,内容随便写,比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import { Result , Button } from "antd" ;import React from "react" ;const Forbidden = ( return ( <Result status ="403" title ="403" subTitle ="抱歉,您无权访问此页面。 " extra ={ <Button type ="primary" href ="/" > 返回主页 </Button > } /> ); }; export default Forbidden ;
2)在 src 下新建 access 目录,所有权限管理相关的代码都放在该目录下,模块化。只要不引入,就不会生效。先在目录中定义权限枚举文件 accessEnum.ts:
1 2 3 4 5 6 7 8 9 10 const ACCESS_ENUM = { NOT_LOGIN : "notLogin" , USER : "user" , ADMIN : "admin" , }; export default ACCESS_ENUM ;
有了枚举类后,可以将全局状态中的默认用户权限改为“未登录”:
1 2 3 4 5 6 const DEFAULT_USER : API .LoginUserVO = { userName : "未登录" , userProfile : "暂无简介" , userAvatar : "/assets/notLoginUser.png" , userRole : AccessEnum .NOT_LOGIN , };
3)在菜单配置文件 menu.tsx 中补充对于权限的配置。比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 { path : "/admin" , name : "管理" , icon : <CrownOutlined /> access : ACCESS_ENUM .ADMIN , children : [ { path : "/admin/user" , name : "用户管理" , access : ACCESS_ENUM .ADMIN , }, ], },
4)编写通用的权限校验方法
为什么?因为菜单组件中要判断权限、权限拦截也要用到权限判断功能,所以抽离成公共模块。新建 checkAccess.ts 文件,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 /** * 检查权限(检查当前登录用户是否具有某个权限) * */ import AccessEnum from "@/access/accessEnum"; import ACCESS_ENUM from "@/access/accessEnum"; const checkAccess = ( loginUser: API.LoginUserVO, needAccess = AccessEnum.NOT_LOGIN, ) => { // 获取当前登录用户拥有的权限(如果没有登录,就代表没有权限) const loginUserAccess = loginUser?.userRole ?? ACCESS_ENUM.NOT_LOGIN; // 如果当前不需要任何权限 if (needAccess === AccessEnum.NOT_LOGIN) { return true; } // 如果页面需要登录才可访问 if (needAccess === AccessEnum.USER) { // 如果用户未登录,表示无权限 if (loginUserAccess === ACCESS_ENUM.NOT_LOGIN) { return false; } } // 如果需要管理员权限才可访问 if (needAccess === AccessEnum.ADMIN) { // 必须要有管理员权限,如果没有,则表示无权限 return loginUserAccess === AccessEnum.ADMIN; } return true; }; export default checkAccess;
有了枚举类后,可以将全局状态中的默认用户权限改为“未登录”:
1 2 3 4 5 6 const DEFAULT_USER : API .LoginUserVO = { userName : "未登录" , userProfile : "暂无简介" , userAvatar : "/assets/notLoginUser.png" , userRole : AccessEnum .NOT_LOGIN , };
3)在菜单配置文件中 menu.tsx 中补充对于权限的配置。比如:
1 2 3 4 5 6 7 8 9 10 11 12 13 { path : "/admin" , name : "管理" , icon : <CrownOutlined /> access : ACCESS_ENUM .ADMIN , children : [ { path : "/admin/user" , name : "用户管理" , access : ACCESS_ENUM .ADMIN , }, ], },
4——编写通用的权限校验方法。
为什么?因为菜单组件中要判断权限、权限拦截也要用到权限判断功能,所以抽离成公共模块。
新建 checkAccess.ts 文件,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import ACCESS_ENUM from "@/access/accessEnum" ;const checkAccess = (loginUser: API.LoginUserVO, needAccess = ACCESS_ENUM.NOT_LOGIN ) => { const loginUserAccess = loginUser?.userRole ?? ACCESS_ENUM .NOT_LOGIN ; if (needAccess === ACCESS_ENUM .NOT_LOGIN ) { return true ; } if (needAccess === ACCESS_ENUM .USER ) { if (loginUserAccess === ACCESS_ENUM .NOT_LOGIN ) { return false ; } } if (needAccess === ACCESS_ENUM .ADMIN ) { if (loginUserAccess !== ACCESS_ENUM .ADMIN ) { return false ; } } return true ; }; export default checkAccess;
可以根据自己的需要,修改判断权限的逻辑。
5)新增权限校验布局 AccessLayout.tsx,逻辑如下: 1.获取到 pathname 和 loginUser 2.根据 pathname 获取到对应的菜单项配置,并获取到所需的权限 3.调用 checkAccess 函数检测是否具有权限。如果有,则正常返回内容;如果没有,返回到无权限页面。
可以先在 menus.tsx 中编写“根据 pathname 获取到菜单项配置” 的函数,使用递归实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 export const findAllMenuItemByPath = (path : string ): MenuDataItem | null => return findMenuItemByPath (menus, path); }; export const findMenuItemByPath = ( menus : MenuDataItem [], path : string , ): MenuDataItem | null => for (const menu of menus) { if (menu.path === path) { return menu; } if (menu.children ) { const matchedMenuItem = findMenuItemByPath (menu.children , path); if (matchedMenuItem) { return matchedMenuItem; } } } return null ; };
然后就可以编写权限校验布局 AccessLayout.tsx,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import { useSelector } from "react-redux" ;import { RootState } from "@/stores" ;import { usePathname } from "next/navigation" ;import checkAccess from "@/access/checkAccess" ;import Forbidden from "@/app/forbidden" ;import React from "react" ;import { findAllMenuItemByPath } from "../../config/menus" ;import AccessEnum from "@/access/accessEnum" ;const AccessLayout : React .FC < Readonly <{ children : React .ReactNode ; }> > = ({ children } ) => { const pathname = usePathname (); const loginUser = useSelector ((state: RootState ) => state.loginUser ); const menu = findAllMenuItemByPath (pathname) || {}; const needAccess = menu?.access ?? AccessEnum .NOT_LOGIN ; const canAccess = checkAccess (loginUser, needAccess); if (!canAccess) { return <Forbidden /> } return <> {children}</> }; export default AccessLayout ;
可以在 RootLayout 中引入,嵌入到 BasicLayout 中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 export default function RootLayout ({ children, }: Readonly<{ children: React.ReactNode; }> ) { return ( <html lang ="zh" > <body > <AntdRegistry > <Provider store ={store} > <InitLayout > <BasicLayout > <AccessLayout > {children}</AccessLayout > </BasicLayout > </InitLayout > </Provider > </AntdRegistry > </body > </html > ); }
6)根据权限控制菜单显隐 新建 menuAccess.ts 文件,提供获取可访问菜单的函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import checkAccess from "@/access/checkAccess" ;import { menus } from "../../config/menus" ;const getAccessibleMenus = (loginUser: API.LoginUserVO, menuItems = menus ) => { return menuItems.filter ((item ) => { if (!checkAccess (loginUser, item.access )) { return false ; } if (item.children ) { item.children = getAccessibleMenus (loginUser, item.children ); } return true ; }); }; export default getAccessibleMenus;
扩展
还有其他实现权限校验的方法,比如使用高阶组件(HOC)在客户端进行权限校验,这种方法会更灵活。
创建一个 HOC 组件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import { useRouter } from 'next/router' ;import { useEffect } from 'react' ;import { useSelector } from 'react-redux' ; export default function withAuth (Component ) { return function AuthenticatedComponent (props ) { const router = useRouter (); const isAuthenticated = useSelector ((state ) => state.auth .isAuthenticated ); useEffect (() => { if (!isAuthenticated) { router.push ('/login' ); } }, [isAuthenticated]); if (!isAuthenticated) { return null ; } return <Component {...props } /> }; }
使用这个 HOC 包裹需要进行权限校验的页面:
1 2 3 4 5 6 7 8 import withAuth from '@/components/withAuth' ;function ProtectedPage ( return <div > This is a protected page.</div > } export default withAuth (ProtectedPage );
通用组件 - Markdown 富文本编辑器 安装命令:
1 2 npm i @bytemd/react npm i @bytemd/plugin-highlight @bytemd/plugin-gfm
在 /src/components 目录中新建 MdEditor 组件,编写代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import { Editor } from "@bytemd/react" ;import gfm from "@bytemd/plugin-gfm" ;import highlight from "@bytemd/plugin-highlight" ;import "bytemd/dist/index.css" ;import "highlight.js/styles/vs.css" ;import "./index.css" ;interface Props { value?: string ; onChange?: (v: string ) => void ; placeholder?: string ; } const plugins = [gfm (), highlight ()];const MdEditor = (props: Props ) => { const { value = "" , onChange, placeholder } = props; return ( <div className ="md-editor" > <Editor value ={value} placeholder ={placeholder} mode ="split" plugins ={plugins} onChange ={onChange} /> </div > ); }; export default MdEditor ;
比如隐藏编辑器中不需要的操作图标(像 GitHub 图标):
1 2 3 .bytemd-toolbar-icon .bytemd-tippy .bytemd-tippy-right :last-child { display : none; }
MdViewer 实例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import { Viewer } from "@bytemd/react" ;import gfm from "@bytemd/plugin-gfm" ;import highlight from "@bytemd/plugin-highlight" ;import "bytemd/dist/index.css" ;import "highlight.js/styles/vs.css" ;import "./index.css" ;interface Props { value?: string ; } const plugins = [gfm (), highlight ()];const MdViewer = (props: Props ) => { const { value = "" } = props; return ( <div className ="md-viewer" > <Viewer value ={value} plugins ={plugins} /> </div > ); }; export default MdViewer ;
bytemd 组件引入 github css 样式
1 npm install github-markdown-css --force
参考上方文档安装之后,在 MdViewer和 MdEditor 中引入样式文件:
1 import 'github-markdown-css/github-markdown-light.css' ;
前端页面开发 前端页面开发,跑通前后端核心业务流程,主要包括:
基础页面开发
核心页面开发
主页
题库列表页
题目搜索页
题库详情页
题目详情页
题目题库绑定(管理员)
1、用户登录页面 可以使用 Ant Design ProComponents 的 ProForm 表单组件,先安装
1 npm i @ant-design/pro-form --force
运用 ProComponents 的登录表单,在其基础上修改即可
2、用户注册页面 与登录页面类似,只不过表单提交逻辑和多了一个输入框
3、用户管理页面 安装表格组件依赖:
1 npm i @ant-design/pro-table --force
扩展 1)用户管理页面可以通过给删除增加二次确认,减少误操作概率。使用 Popconfirm 组件可轻松实现:https://ant-design.antgroup.com/components/popconfirm-cn
2)用户管理页面实现多列排序功能 前端 ProTable 已经默认支持了,通过 request 函数的 sort 参数可以获取到排序条件,需要让后端支持处理多列排序。
4、题目管理页面 表格列配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 const columns : ProColumns <API .Question >[] = [ { title : "id" , dataIndex : "id" , valueType : "text" , hideInForm : true , }, { title : "标题" , dataIndex : "title" , valueType : "text" , }, { title : "内容" , dataIndex : "content" , valueType : "text" , hideInSearch : true , width : 240 , }, { title : "答案" , dataIndex : "answer" , valueType : "text" , hideInSearch : true , width : 640 , }, { title : "标签" , dataIndex : "tags" , valueType : "select" , fieldProps : { mode : "tags" , } }, { title : "创建用户" , dataIndex : "userId" , valueType : "text" , hideInForm : true , }, { title : "创建时间" , sorter : true , dataIndex : "createTime" , valueType : "dateTime" , hideInSearch : true , hideInForm : true , }, { title : "编辑时间" , sorter : true , dataIndex : "editTime" , valueType : "dateTime" , hideInSearch : true , hideInForm : true , }, { title : "更新时间" , sorter : true , dataIndex : "updateTime" , valueType : "dateTime" , hideInSearch : true , hideInForm : true , }, { title : "操作" , dataIndex : "option" , valueType : "option" , render : (_, record ) => ( <Space size ="middle" > <Typography.Link onClick ={() => { setCurrentRow(record); setUpdateModalVisible(true); }} > 修改 </Typography.Link > <Typography.Link type ="danger" onClick ={() => handleDelete(record)}> 删除 </Typography.Link > </Space > ), }, ];
处理特殊逻辑
1)自定标签渲染,把字符串转为标签列表:
1 2 3 4 5 6 7 8 9 10 11 12 { title : "标签" , dataIndex : "tags" , valueType : "select" , fieldProps : { mode : "tags" , }, render : (_, record ) => { const tagList = JSON .parse (record.tags || "[]" ); return <TagList tagList ={tagList} /> }, },
tagList 是用于渲染标签列表的组件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import { Tag } from "antd" ;import "./index.css" ;interface Props { tagList?: string []; } const TagList = (props: Props ) => { const { tagList = [] } = props; return ( <div className ="tag-list" > {tagList.map((tag) => { return <Tag key ={tag} > {tag}</Tag > ; })} </div > ); }; export default TagList ;
2)需要修改题目内容和答案的输入框为我们封装的 MdEditor 编辑器,可参考 ProTable 官方文档的 自定义表单项渲染。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 { title : "内容" , dataIndex : "content" , valueType : "text" , hideInSearch : true , width : 240 , renderFormItem : ( _, { type , defaultRender, formItemProps, fieldProps, ...rest }, form, ) => return ( <MdEditor // 组件的配置 {...fieldProps } /> ); }, },
3)注意,更新数据时,需要将 tags 转换成数组后作为表单初始值,否则无法正常同步到表单。可以在 UpdateModal 中自己 定义初始值对象:
1 2 3 4 5 let initValues = { ...oldData };if (oldData.tags ) { initValues.tags = JSON .parse (oldData.tags ) || []; }
然后在 ProTable 组件中使用初始值对象:
1 2 3 4 5 6 7 <ProTable type ="form" columns={columns} form={{ initialValues : initValues, }} />
核心页面开发 主页开发 利用 Title 组件显示标题,注意引入的库为 import Title from "antd/es/typography/Title";
利用 组件是组件变为流式布局,自定义题目列表和题库列表组件,并根据后端返回的值填入到对应的组件中
注意,主页为服务端渲染,但是主页用到的题目列表组件和题库列表组件需要单独抽离出来,并且为客户端渲染
ProTable 组件 1、对于 ProComponents 的表格 ProTable 组件,可以通过 hideInSearch: true,hideInForm: true,来显示控制某些列是否要展示在搜素框和表单中。
2、另外 ProTable 渲染多个标签时可以自己实现 render 函数,并自己封装标签列表组件再将标签列表传入其中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 { title : "标签" , dataIndex : "tags" , valueType : "select" , fieldProps : { mode : "tags" , }, render : (_, record ) => { const tags = JSON .parse (record.tags || "[]" ); return <TagList tags ={tags}/ > }, hideInSearch : true , hideInForm : true , },
3、ProTable 表格中的数据的数据是通过 request 函数请求远程获取的,在 return 中我们需要将 total 和 data 的值改为后端返回的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 request={async (params, sort, filter) => { const sortField = Object .keys (sort)?.[0 ]; const sortOrder = sort?.[sortField] ?? undefined ; const {data, code} = await listQuestionByPageUsingPost ({ ...params, sortField, sortOrder, ...filter, } as API .QuestionQueryRequest ); const newData = data?.records || []; const newTotal = data?.total || 0 ; return { success : code === 0 , data : newData, total : newTotal, }; }} columns={columns}
demo:
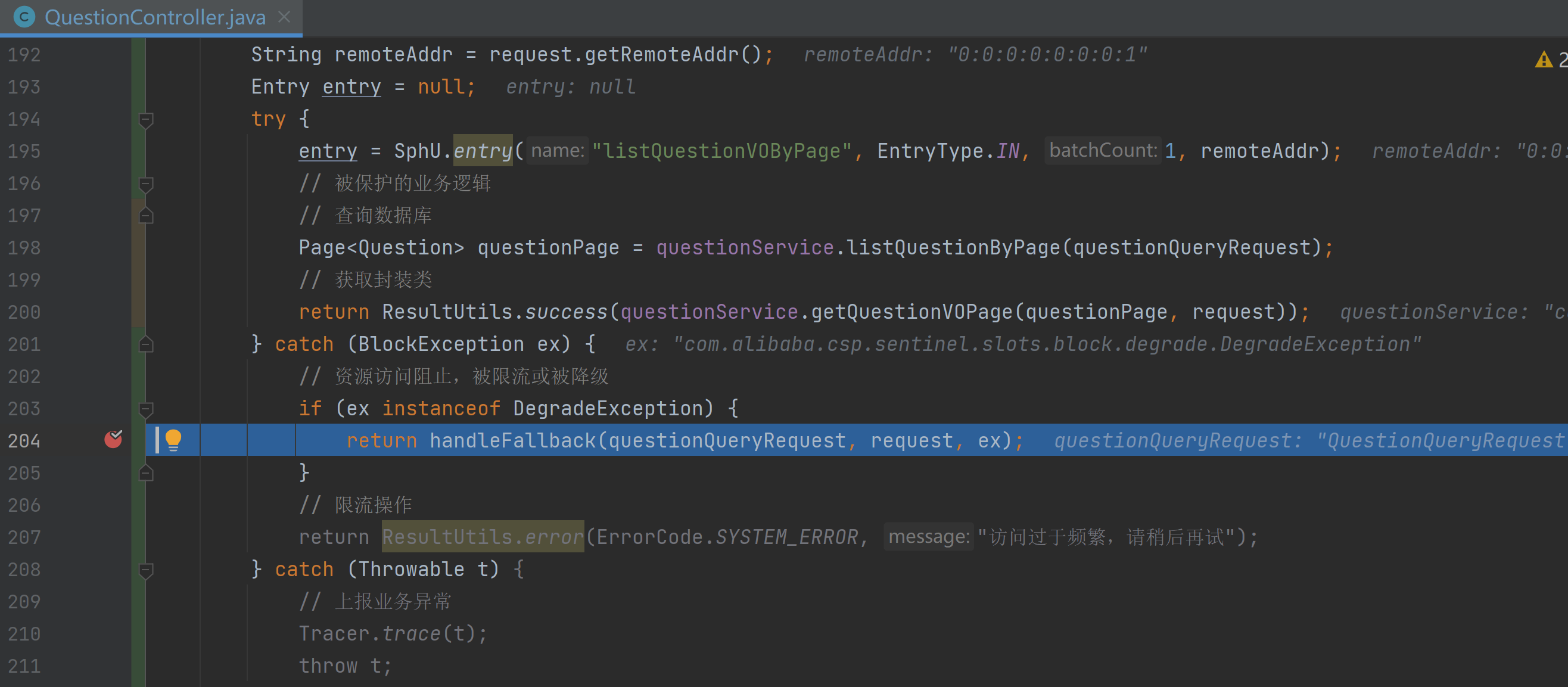
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 "use client" ;import React , {useState} from 'react' ;import {ProColumns , ProTable } from "@ant-design/pro-table" ;import {listQuestionByPageUsingPost} from "@/api/questionController" ;import TagList from "@/components/TagList" ;import {TablePaginationConfig } from "antd" ;interface Props { defaultQuestionList?: API .QuestionVO [], defaultTotal?: number , } const QuestionTable : React .FC = (props: Props ) => { const {defaultQuestionList, defaultTotal} = props; const [questionList, setQuestionList] = useState<API .QuestionVO []>(defaultQuestionList || []); const [total, setTotal] = useState<number >(defaultTotal || 0 ); const columns : ProColumns <API .Question >[] = [ { title : '标题' , dataIndex : 'title' , valueType : 'text' , hideInSearch : true , hideInForm : true , }, { title : "标签" , dataIndex : "tags" , valueType : "select" , fieldProps : { mode : "tags" , }, render : (_, record ) => { const tags = JSON .parse (record.tags || "[]" ); return <TagList tags ={tags}/ > }, hideInSearch : true , hideInForm : true , }, { title : '创建人' , dataIndex : 'userId' , valueType : 'text' , hideInSearch : true , hideInForm : true , }, ]; return ( <div className ="questionTable" > <ProTable<API.QuestionVO > rowKey="key" size="large" search={{ labelWidth: "auto", }} pagination={{ pageSize: 12, showTotal: (total) => `总共${total}条`, showSizeChanger: false, total, } as TablePaginationConfig} request={async (params, sort, filter) => { const sortField = Object.keys(sort)?.[0]; const sortOrder = sort?.[sortField] ?? undefined; const {data, code} = await listQuestionByPageUsingPost({ ...params, sortField, sortOrder, ...filter, } as API.QuestionQueryRequest); // 更新结果 const newData = data?.records || []; const newTotal = data?.total || 0; setQuestionList(newData); setTotal(newTotal); return { success: code === 0, data: newData, total: newTotal, }; }} columns={columns} /> </div > ); }; export default QuestionTable;
4、ProTable 组件的 form 参数可以通过 initialValus 参数配置初始值
1 2 3 form={{ initialValues : defaultSearchParams }}
ProTable 组件还支持多选表格项,可以通过配置 rowSelection、tableAlertRender、tableAlertOptionRender 等属性实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 <ProTable<TableListItem> columns={columns} rowSelection={{ // 自定义选择项参考: https://ant.design/components/table-cn/#components-table-demo-row-selection-custom // 注释该行则默认不显示下拉选项 selections: [Table.SELECTION_ALL, Table.SELECTION_INVERT], defaultSelectedRowKeys: [1], }} tableAlertRender={({ selectedRowKeys, selectedRows, onCleanSelected, }) => { console.log(selectedRowKeys, selectedRows); return ( <Space size={24}> <span> 已选 {selectedRowKeys.length} 项 <a style={{ marginInlineStart: 8 }} onClick={onCleanSelected}> 取消选择 </a> </span> <span>{`容器数量: ${selectedRows.reduce( (pre, item) => pre + item.containers, 0, )} 个`}</span> <span>{`调用量: ${selectedRows.reduce( (pre, item) => pre + item.callNumber, 0, )} 次`}</span> </Space> ); }} tableAlertOptionRender={() => { return ( <Space size={16}> <a>批量删除</a> <a>导出数据</a> </Space> ); }} dataSource={tableListDataSource} scroll={{ x: 1300 }} options={false} search={false} pagination={{ pageSize: 5, }} rowKey="key" headerTitle="批量操作" toolBarRender={() => [<Button key="show">查看日志</Button>]} />
next.js 中在组件形参中加上 searchParams 默认就能获取搜索参数的值
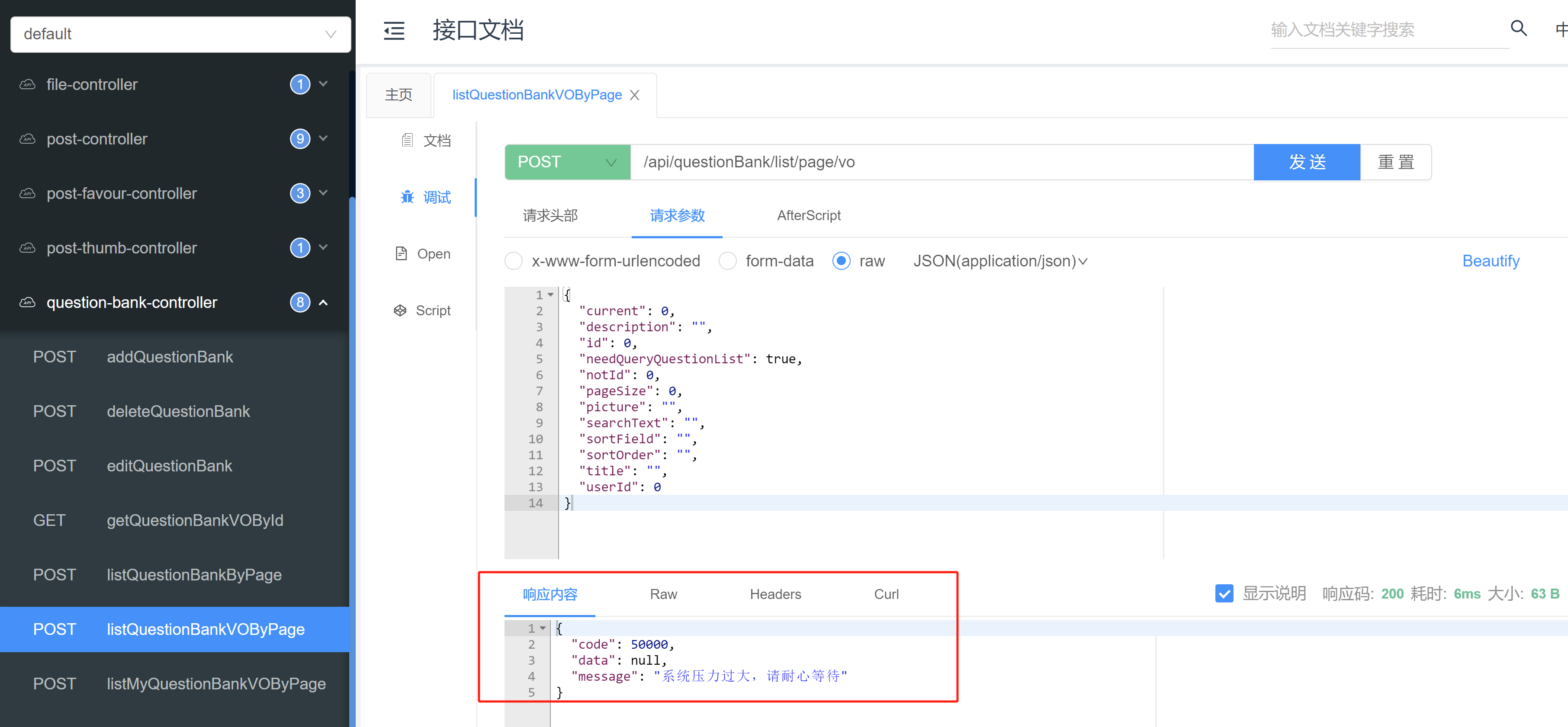
题库详情页 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 "use server" ;import "./index.css" ;import {Avatar , Button , Card , message} from "antd" ;import {getQuestionBankVoByIdUsingGet} from "@/api/questionBankController" ;import Meta from "antd/es/card/Meta" ;import Paragraph from "antd/es/typography/Paragraph" ;import QuestionList from "@/components/QuestionList" ;import Title from "antd/es/typography/Title" ;export default async function BankPage ({ params } ) { const { questionBankId } = params; let bank = undefined ; try { const res = await getQuestionBankVoByIdUsingGet ({ id : questionBankId, needQueryQuestionList : true , pageSize : 200 , }); bank = res?.data ; } catch (e) { message.error ("获取题目失败," + e.message ); } if (!bank) { return <div > 获取题库详情失败,请刷新重试</div > } let firstQuestionId; if (bank.questionPage ?.records && bank.questionPage .records .length > 0 ) { firstQuestionId = bank.questionPage .records [0 ]; } return ( <div id ="bankPage" className ="max-width-content" > <Title level ={2} > {bank.name}</Title > <Card > <Meta avatar ={ <Avatar src ={bank.picture} size ={72}/ > } title={ <Title level ={3} style ={{marginBottom: 0 }}> {bank.title} </Title > } description={ <> <Paragraph type ="secondary" ellipsis ={{rows: 1 }} style ={{marginBottom: 0 }}> {bank.description} </Paragraph > <Button type ="primary" shape ="round" href ={ `/bank /${questionBankId }/question /${firstQuestionId }`} target ="_blank" disabled ={!firstQuestionId} > 开始刷题</Button > </> } /> </Card > <div style ={{marginBottom: 16 }}> </div > <QuestionList questionList ={bank.questionPage.records ?? []} cardTitle ={ `題目列表 (${ bank.questionPage ?.total ?? 0 })`} questionBankId ={questionBankId}/ > </div> ); }
题目详情页 需求:有两种不同的题目详情页
1.从题库进入的题目详情页:左侧需要展示题库内的题目列表。路由:/bank/[bankld]/question/[questionld
2.从其他位置(比如主页、搜索页)进入的题目详情页,不需要展示题库列表。路由:/question/[questionld] 这两个页面极为相似,可以直接开发额外展示题目列表的题目详情页,另一个页面复制并删减即可
为什么题目详情页的标题要是一级的 => 为了被搜索引擎爬虫收录
对于 Ant Design 组件库,凡是某个组件定义了 React.Node 都是可以传组件的
Menu 组件如何实现选中菜单高亮?
通过往 selectedKeys 属性传 数组实现对应的菜单项高亮
1 <Menu items={questionMenuItemList} selectedKeys={[question.id ]}/>
1、可以根据 useForm 函数获取 form 表的参数
2、根据 setFieldValue 函数设置表单项的值
1 2 const [form] = Form .useForm ();form.setFieldValue ("questionBankIdList" , questionBankIdList);
3、Select 组件支持传入 options 属性指定下拉框所选项
1 2 3 4 5 6 options={questionBankList.map ((questionBank ) => { return { label : questionBank.title , value : questionBank.id , }; })}
4、Select 组件还支持传入 onSelect 函数和 onDeselect 函数,使得选中、取消选中值时编写相应逻辑,比如给后端发请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 onSelect={async (value) => { const hide = message.loading('正在更新'); try { await addQuestionBankQuestionUsingPost({ questionId, questionBankId: value, }); hide(); message.success('绑定题库成功'); return true; } catch (error: any) { hide(); message.error('绑定题库失败,' + error.message); return false; } }}
扩展思路:
1、预渲染 通过 官方文档 了解 Next.js 的 prefetch 预渲染机制,进行性能优化。
比如页面内的链接过多时,预渲染次数会很多,可以将 prefetch 关闭来减少预渲染:
2、Metadata Next.js 支持通过 Metadata 设置页面的 TDK(标题、描述、关键词)等网页元信息。可参考官方文档:https://nextjs.org/docs/app/building-your-application/optimizing/metadata
3、请求缓存 Next.is 扩展了原生的 fetch,支持请求数据的服务端缓存,是提升性能、减少资源占用的好方法。可以参考官方获取数据的文档:https://nextjs.org/docs/app/building-your-application/data-fetching但是,我们项目中使用的 Axios 库是不支持缓存的!有其他的方式来实现缓存:1)可以在 getStaticProps 或 getServerSideProps 中使用 Axios 来获取数据,然后通过 Next.js 的 revalidate选项来控制页面或数据的重新生成时间。
4、并发请求
如果同一个页面要多次请求后端,串行可能会很慢,导致页面迟迟不返回。因此可以并发调用多个接口来获取数据,使用 promise.all 语法即可。
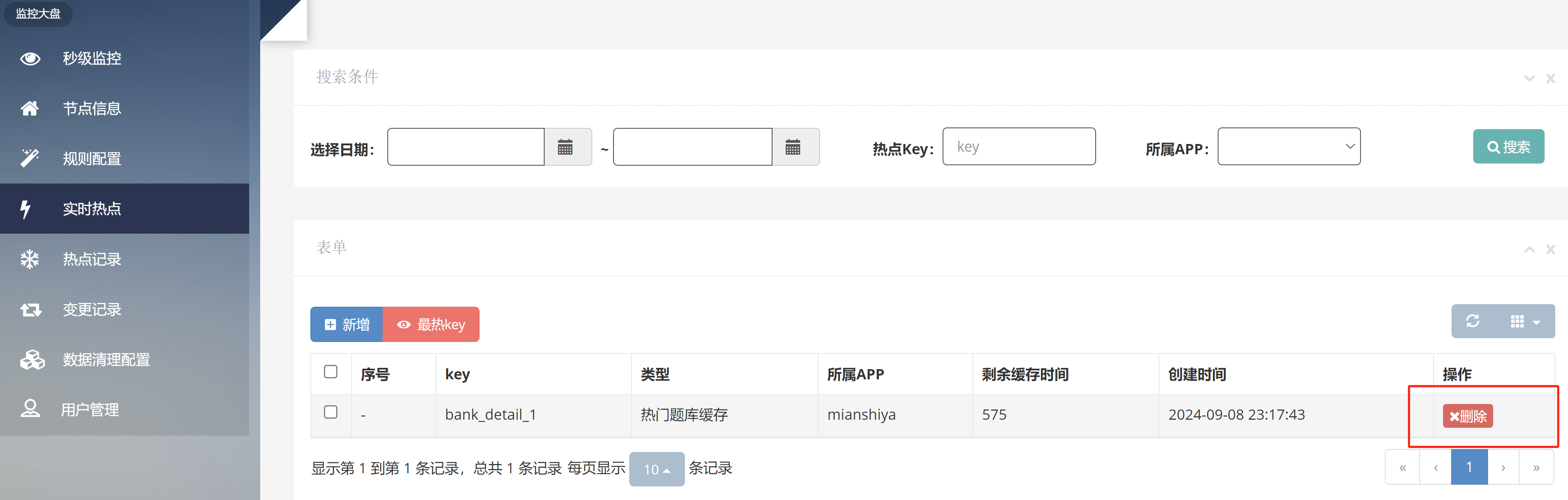
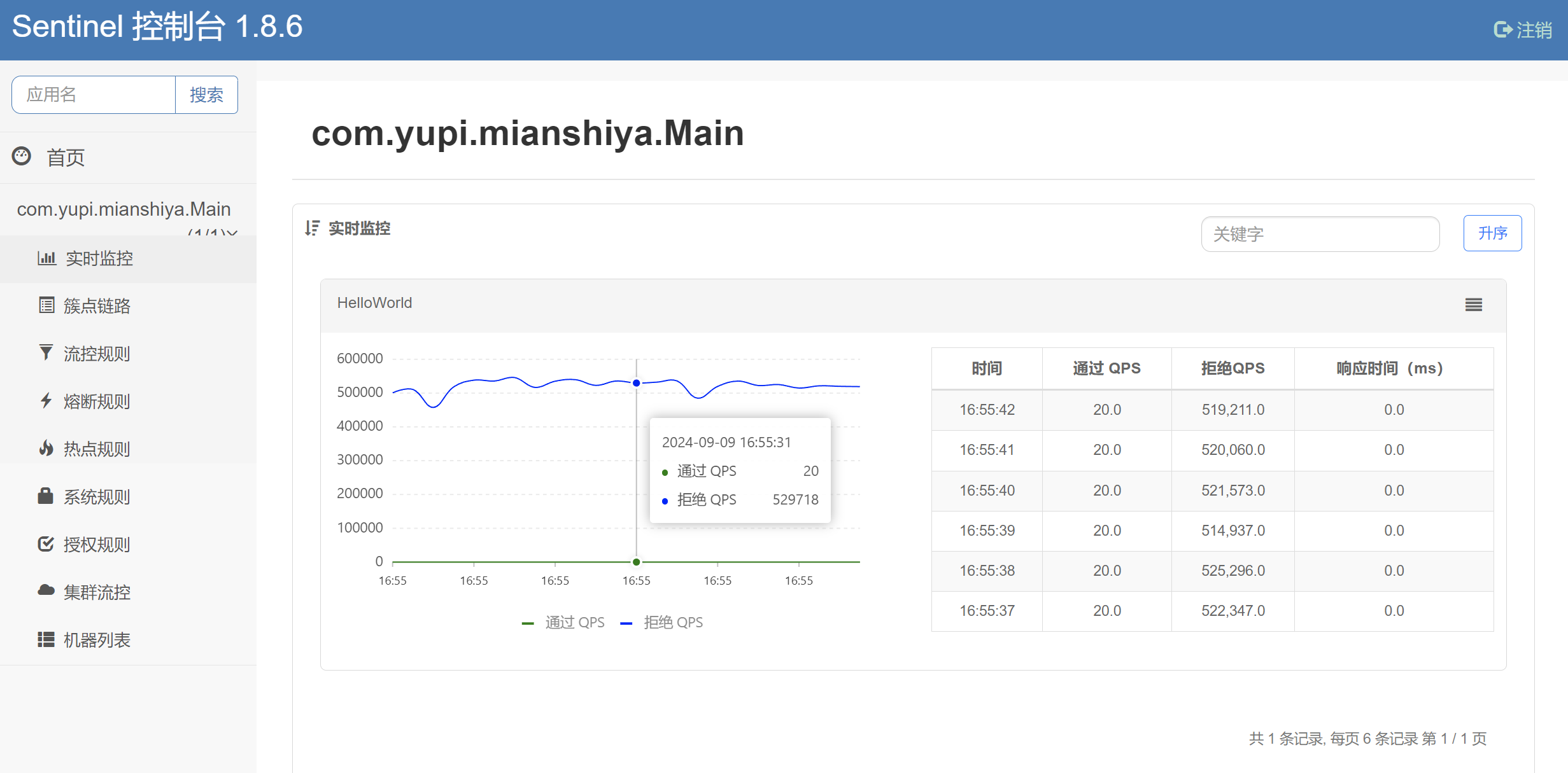
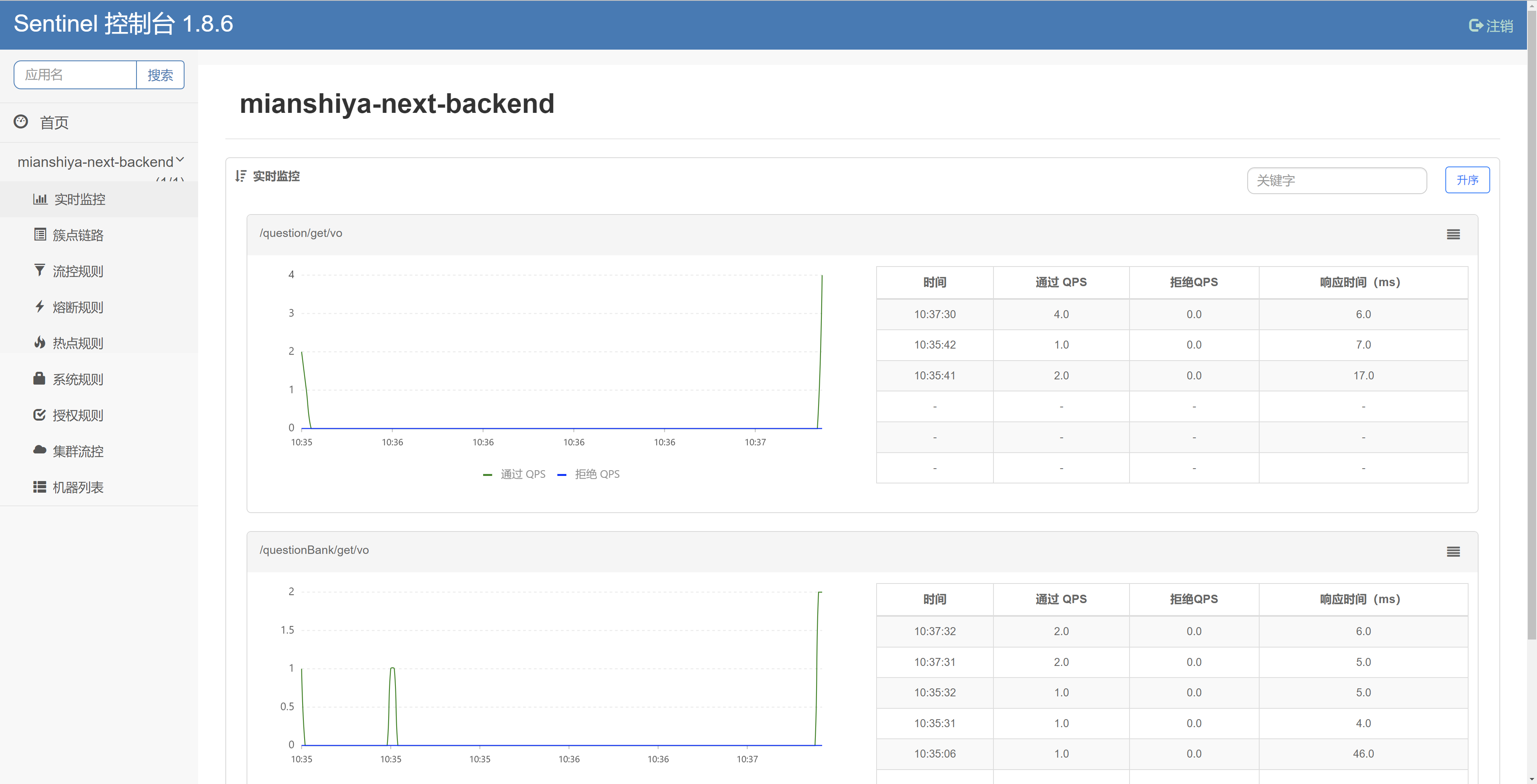
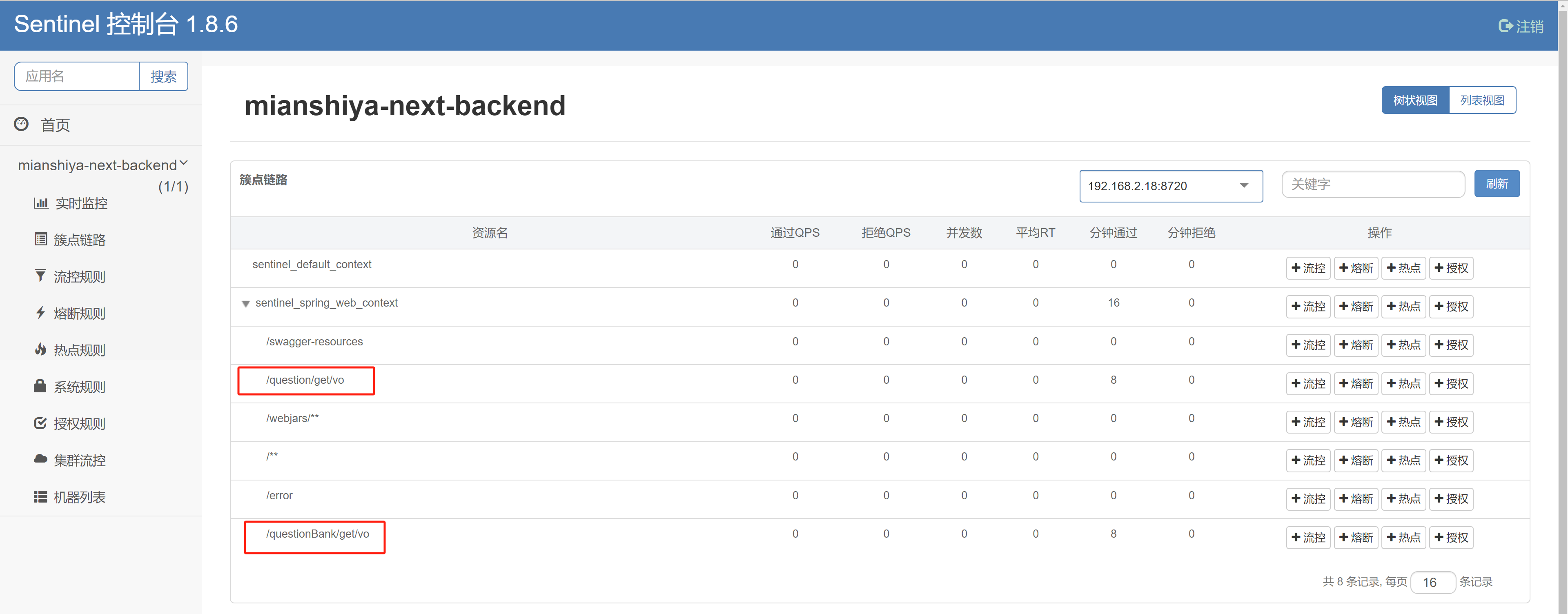
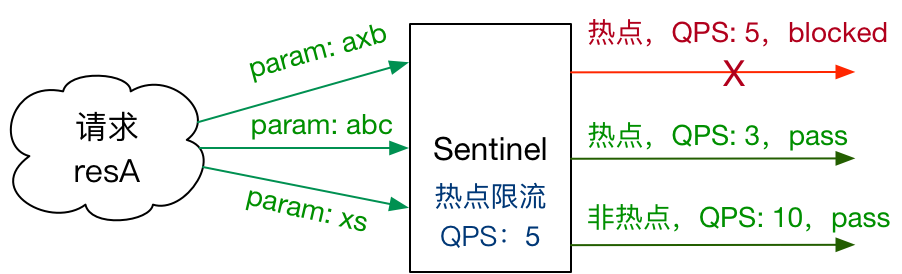
用户刷题记录日历 需求分析 为了鼓励用户多在网站上刷题,并且能自主复盘学习情况,增加成就感,需要支持用户刷题记录日历功能。
每个用户有自己的签到记录,具体拆解为 2 个子需求:
用户每日首次浏览题目,算作是签到,会记 统中。
用户可以在前端以图表的形式查看自己在 某个年份 的刷题签到记录(每天是否有签到)
方案设计 后端方案 — 基于数据库
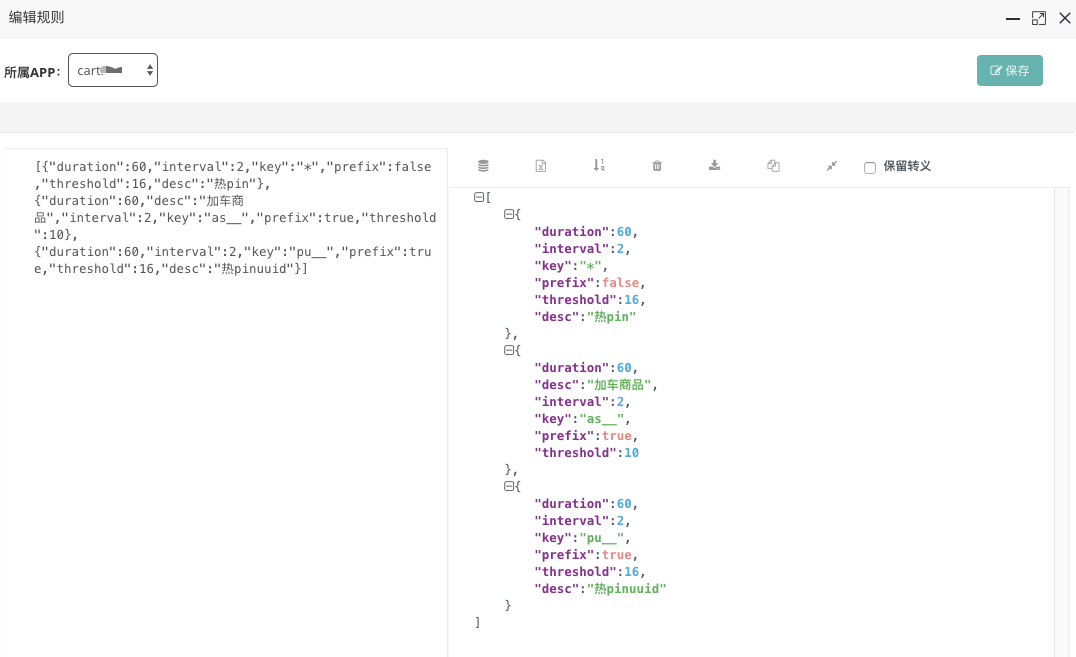
1 2 3 4 5 6 7 CREATE TABLE user_sign_in ( id BIGINT AUTO_INCREMENT PRIMARY KEY, userId BIGINT NOT NULL , signDate DATE NOT NULL , createdTime TIMESTAMP DEFAULT CURRENT_TIMESTAMP , UNIQUE KEY uq_user_date (userId, signDate) );
通过唯一索引,可以确保同一用户在同一天内只能签到一次。通过下面的 SQL 即可查询用户的签到记录:
1 2 SELECT signDate FROM user_sign_in WHERE userId = ? AND signDate BETWEEN ?AND ?;
优点:原理简单,容易实现,适用于用户量较小的系统
缺点:随着用户量和数据量增大,对数据库的压力增大,直接查询数据库性能较差。除了单接口的响应会增加,可能整个系统都会被其拖垮。
后端方法—基于 Redis Set
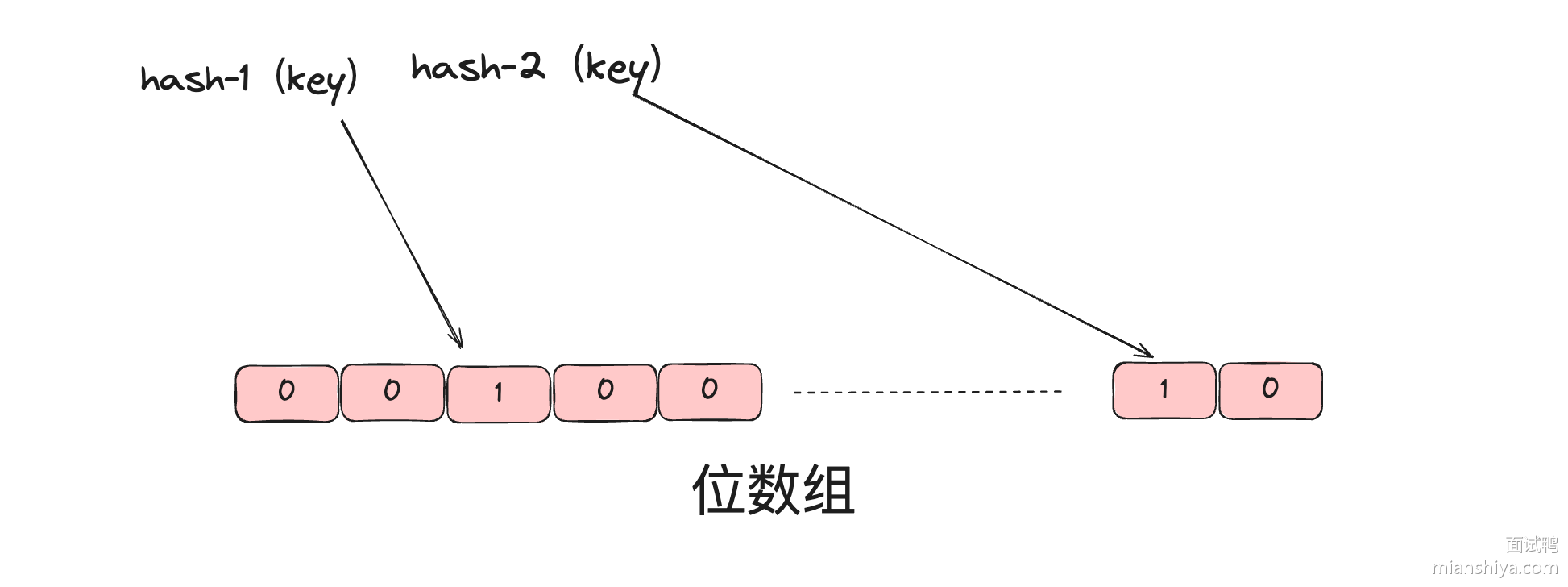
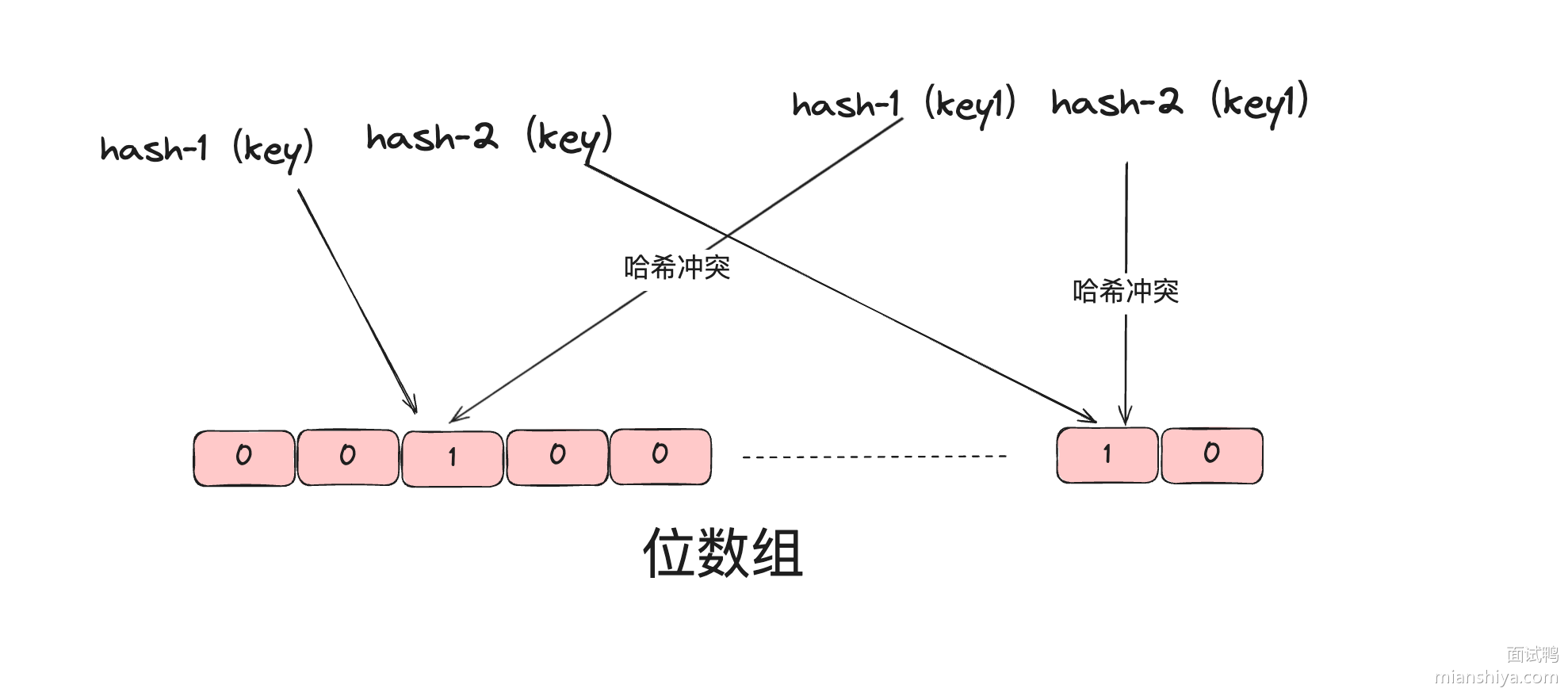
可以利用内存缓存加速读写,常用的本地缓存是 Caffeine,分布式缓存是 Redis。由于每个用户会有多个签到记录,很适合使用 Redis 的 Set 类型存储,每个用户对应一个键,Set 内的每个元素为签到的具体日期。
Redis Key的设计为:user:signins:{userId}
其中:
user 是业务领域前缀
signins 是具体操作或功能
{userld}表示每个用户,是动态值
如果 Redis 被多个项目公用,还可以在开头增加项目前缀区分,比如 mianshiya:user:signins:{userId}。
该方案的优点:Set 数据结构天然支持去重,适合存储和检索打卡记录。
缺点:上述设计显然存储了很多重复的字符串,针对海量数据场景,需要考虑内存的占用量。
比如下列数据:
1 2 key = user:signins:123 value = ["2024-09-01", "2024-09-02", "2024-10-01", "2024-10-02"]
其中年份被重复存储。
为了减少内存占用,还可以在 key 中增加更多日期层级,比如 user:signins:{year}:{userId},实例命令如下:
1 2 SADD user:signins:2024:123 "09-01" SADD user:signins:2024:123 "10-01"
这样一来,不仅节约了内存,也便于管理,可以轻松查询某个用户在某个年份的签到情况。
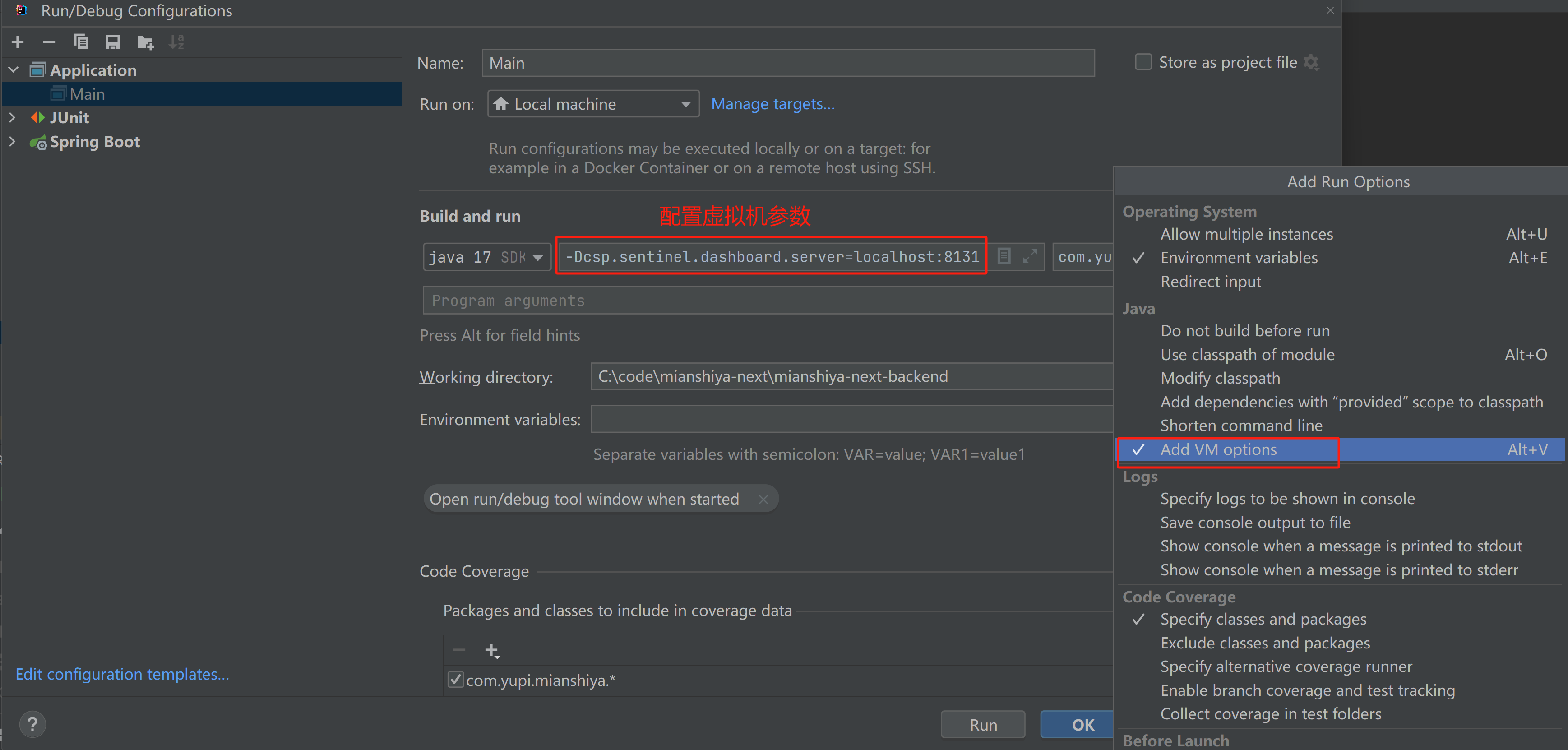
💡 存储 100 万个用户 的 365 天 签到记录,使用 Redis 集合类型来存储每个用户的签到信息,每个用户需要大约 1880 字节1608639807578177538_0.9860546375639874 的空间,总共需要大约 1.88GB 的内存空间,相比数据库节约了 10 倍左右。
后端方案—BitMap位图
位图是一个用位表示数据的紧凑数据结构,每个位可以存储两个值:0 或 1,常用于表示某种状态。在签到系统中,可以用 1 表示已签到,0 表示未签到。以用户的 id 和年份作为 key,1 和 0 表示用户在一年中是否签到,bitmap 本质是有 Zset 实现的,所以我们可以这么是设计,假如用户在第一天签到了,那么 zset 索引为 0 的位置改为 1,假如在第 30 天签到了,那么 zset 索引为 29 的位置改为 1,其余就为 0。最后我们遍历 Zset 集合,根据值为 1 的索引与本年的第一天进行计算,从而算出签到的日期。
现代计算机体系结构通常以字节(8位)作为最小寻址单位,那么上述的 bit 是如何存储的呢?
答案就是 打包 。
对每一位操作时,要使用位运算进行访问,所以上述的图实际应该改成:
💡 对于刷题签到记录场景,一个用户存储一年的数据仅需占用 46 字节,因为 46 * 8 = 368,能覆盖 365 天的记录。那一百万用户也才占用 43.8 MB,相比于 Redis Set 结构节约了 40 多倍存储空间!
1000w 个用户也才占用 438 MB!恭喜你,设计出了一个低成本支持千万用户的系统!
当然,我们没必要自己通过 int 等类型实现 Bitmap,JDK 自带了 BitSet 类、Redis 也支持 Bitmap 高级数据结构。考虑到项目的分布式、可扩展性,采用 Redis 的 Bitmap 实现。
综上所述,Redis Key 的设计为:user:signins:{年份}:{userId}
在 Java 程序中,还可以使用 Redisson 库提供的现成的 RBitSet,开发成本也很低。
这种方案的优点:内存占用极小,适合大规模用户和日期的场景。
缺点:需要熟悉位图操作,不够直观。
前端方案 要明确前端展示签到记录日历所需的数据类型,后端才好设计接口的返回值,因此方案设计阶段要考虑全面。 复杂的展示组件肯定不用自己开发,只要是图表(可视化),就可以优先考虑使用 Apache Echarts 前端可视化库,有3种可行的组件:
1.基础日历图:https://echarts.apache.org/examples/zh/editor.html?c=calendar-simple
2.日历热力图:https://echarts.apache.org/examples/zh/editor.htm!?c=calendar-heatmap,跟上一个图的区别就是鼠标放上去可以展示具体的热力值,热力值越高,图块的颜色越深。
3.日历图:https://echarts.apache.org/examples/zh/editor.html?c=calendar-charts
本项目选择基础日历图即可,不涉及热力数值的区分(只有0和1签到/未签到的区别):
如下是官方 Demo 的数据格式:
1 2 3 4 5 6 for (let time = date; time <= end; time += dayTime) { data.push ([ echarts.time .format (time, '{yyyy}-{MM}-{dd}' , false ), Math .floor (Math .random () * 10000 ) ]); }
很明显得到的数据是一个二位数组,每个元素表示对应的日期和热力值,很明显我们后端就要返回如上的结构的数据
1 2 3 4 5 [ ['2017-01-01' , 3456 ], ['2017-01-02' , 8975 ], ... ]
但回归我们的项目,用 Bitmap 每天最多只有一次记录,相当于只有 0 和 1。因此可以调整 Apache ECharts 图表的配置来调整热力值的范围,从而控制颜色深浅。还支持调整颜色:
1 2 3 4 5 6 7 8 visualMap : { show : false , min : 0 , max : 1 , inRange : { color : ['#efefef' , 'lightgreen' ] }, },
效果如图:
后端开发 因此我们要开发两个接口
用户添加签到记录接口
查询刷题签到记录接口
1、引入Redisson
Redisson 是一个基于 Redis 的开源分布式 Java 数据库客户端,提供了类似 Java 标准库的数据结构(如 Map、Set、List、BitSet 等)在分布式环境下的实现。它不仅支持基本的 Redis 操作,还提供了高级功能,如分布式锁、同步器、限流器、缓存等,简化了在分布式系统中使用 Redis 进行数据共享和并发控制的复杂性。
1)引入 Redisson 依赖
1 2 3 4 5 <dependency > <groupId > org.redisson</groupId > <artifactId > redisson</artifactId > <version > 3.17.5</version > </dependency >
2)编写 Redisson 配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Configuration @ConfigurationProperties(prefix = "spring.redis") @Data public class RedissonConfig { private String host; private String port; private String password; @Bean public RedissonClient redissonClient () { Config config = new Config (); String redisAddress = String.format("redis://%s:%s" , host, port); config.useSingleServer().setAddress(redisAddress).setDatabase(7 ).setPassword(password); RedissonClient redisson = Redisson.create(config); return redisson; } }
2、开发刷题签到记录接口
1 2 3 4 5 6 7 8 9 10 public boolean addUserSignIn (HttpServletRequest request) { User loginUser = this .getLoginUser(request); Long userId = loginUser.getId(); RBitSet bitSet = redisson.getBitSet(RedisConstant.getUserSignInRedisKey(userId)); int offset = LocalDateTime.now().getDayOfYear(); if (!bitSet.get(offset)) { return bitSet.set(offset); } return true ; }
3、开发签到记录查询接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public Map<LocalDate, Boolean> getSignInRecord (long userId, Integer year) { if (year == null ) { year = DateUtils.getNowYear(); } String key = RedisConstant.getUserSignInRedisKey(year, userId); RBitSet signInBitSet = redisson.getBitSet(key); Map<LocalDate, Boolean> result = new LinkedHashMap <>(); int totalDays = Year.of(year).length(); for (int dayOfYear = 1 ; dayOfYear <= totalDays; dayOfYear++) { LocalDate currentDate = LocalDate.ofYearDay(year, dayOfYear); boolean hasRecord = signInBitSet.get(dayOfYear); result.put(currentDate, hasRecord); } return result; }
性能优化
由于每次查询用户的签到记录,都要访问 Redis 去查看是否有签到记录,每一个循环就要请求一次 Redis,这样就导致性能十分低下,因此我们可以通过本地缓存来降低对 Redis 的压力。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public Map<LocalDate, Boolean> getSignInRecord (long userId, Integer year) { if (year == null ) { year = DateUtils.getNowYear(); } String key = RedisConstant.getUserSignInRedisKey(year, userId); RBitSet signInBitSet = redisson.getBitSet(key); BitSet bitSet = signInBitSet.asBitSet(); Map<LocalDate, Boolean> result = new LinkedHashMap <>(); int totalDays = Year.of(year).length(); for (int dayOfYear = 1 ; dayOfYear <= totalDays; dayOfYear++) { LocalDate currentDate = LocalDate.ofYearDay(year, dayOfYear); boolean hasRecord = bitSet.get(dayOfYear); result.put(currentDate, hasRecord); } return result; }
2、刷题记录返回优化
从返回结果看出传输的数据较多、计算时间较长、带宽占用较大,效率低
实际上我们继续将有刷题记录的日期返回给前端就好了,随后再由前段渲染刷过题的日期,其余就是没刷过题的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public List<Integer> getUserSignInRecord (long userId, Integer year) { if (year == null ) { LocalDate date = LocalDate.now(); year = date.getYear(); } String key = RedisConstant.getUserSignInRedisKey(year, userId); RBitSet signInBitSet = redissonClient.getBitSet(key); BitSet bitSet = signInBitSet.asBitSet(); List<Integer> dayList = new ArrayList <>(); int totalDays = Year.of(year).length(); for (int dayOfYear = 1 ; dayOfYear <= totalDays; dayOfYear++) { boolean hasRecord = bitSet.get(dayOfYear); if (hasRecord) { dayList.add(dayOfYear); } } return dayList; }
3、计算优化
上述代码中,我们使用循环来遍历所有年份,而循环是需要消耗CPU 计算资源的。在 Java 中的 Bitset 类中,可以使用 nextsetBit(int fromIndex)和 nextclearBit(int fromIndex)方法来获取从指定索引开始的下一个 已设置(即为 1) 或 未设置(即为 0) 的位。主要是 2 个方法: nextsetBit(int fromIndex):从 fromIndex 开始(包括 fromIndex 本身)寻找下一个被设置为1的位。如果找到了,返回该位的索引;如果没有找到,返回-1。
nextclearBit(int fromIndex):从 fromIndex 开始(包括 fromIndex本身)寻找下一个为0的位。如果找到了 返回该位的索引;如果没有找到,返回一个大的整数值。
使用 nextSetBit,可以跳过无意义的循环检查,通过位运算来获取被设置为1的位置,性能更高。
修改后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public List<Integer> getUserSignInRecord (long userId, Integer year) { if (year == null ) { LocalDate date = LocalDate.now(); year = date.getYear(); } String key = RedisConstant.getUserSignInRedisKey(year, userId); RBitSet signInBitSet = redissonClient.getBitSet(key); BitSet bitSet = signInBitSet.asBitSet(); List<Integer> dayList = new ArrayList <>(); int index = bitSet.nextSetBit(0 ); while (index >= 0 ) { dayList.add(index); index = bitSet.nextSetBit(index + 1 ); } return dayList; }
优化小结 优化小结 本功能的性能优化也是有代表性的,总结出来几个实用优化思路:
减少网络请求或调用次数
减少接口传输数据的体积
减少循环和计算
通过客户端计算减少服务端的压力
前端开发 1、引入 ECharts 组件库
安装 ECharts:https://echarts.apache.org/zh/index.html1608639807578177538_0.43979611555120557
和 React ECharts 可视化库:https://github.com/hustcc/echarts-for-react
1 2 npm install --save echarts --force npm install --save echarts-for-react --force
2、用户中心页面开发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <Dropdown menu={{ items : [ { key : "userCenter" , icon : <UserOutlined /> label : "个人中心" , }, { key : "logout" , icon : <LogoutOutlined /> label : "退出登录" , }, ], onClick : async (event : { key : React .Key }) => { const { key } = event; if (key === "logout" ) { userLogout (); } else if (key === "userCenter" ) { router.push ("/user/center" ); } }, }} > {dom} </Dropdown >
页面结构可以通过如下组件快速完成:
栅格响应式布局:https://ant-design.antgroup.com/components/grid-cn#grid-demo-responsive 左侧用户信息,Card.Meta 组件:https://ant-design.antgroup.com/components/card-cn#card-demo-meta 右侧内容区域,带页签的卡片:https://ant-design.antgroup.com/components/card-cn#card-demo-tabs
3、封装日历组件
1)参考 React ECharts 的 官方文档 来使用 ECharts 组件,把 Demo 代码复制到新建的组件文件中。
2)在用户中心页面中引入组件,便于查看效果:
1 2 3 {activeTabKey === "record" && <> <CalendarChart /> </>
3)定义签到日期数组变量,将数组转换为图表需要的数据。其中,对日期的处理需要用到 dayjs 库:
1 2 3 4 5 6 7 8 9 10 11 12 const [dataList, setDataList] = useState<number []>([]);const year = new Date ().getFullYear ();const optionsData = dataList.map ((dayOfYear, index ) => { const dateStr = dayjs (`${year} -01-01` ) .add (dayOfYear - 1 , "day" ) .format ("YYYY-MM-DD" ); return [dateStr, 1 ]; });
4)参考 Echarts 的官方 Demo 开发前端日历图:https://echarts.apache.org/examples/zh/editor.html?c=calendar-simple
先在 Demo 页面里调整好效果,得到 options 选项。
调整好的 options 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 const options = { visualMap : { show : false , min : 0 , max : 1 , inRange : { color : ["#efefef" , "lightgreen" ], }, }, calendar : { range : year, left : 20 , cellSize : ['auto' , 16 ], yearLabel : { position : "top" , formatter : `${year} 年刷题记录` , } }, series : { type : "heatmap" , coordinateSystem : "calendar" , data : optionsData, }, };
5)获取数据:前端调用 OpenAP| 生成新的刷题签到记录相关接口,调用并得到 dataList 即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const fetchDataList = async ( try { const res = await getUserSignInRecordUsingGet ({ year, }); setDataList (res.data || []); } catch (e) { message.error ("获取刷题签到记录失败," + e.message ); } }; useEffect (() => { fetchDataList (); }, []);
4、执行签到
由于获取题目详情接口是在服务端渲染,拿不到用户登录态,所以建议在客户端额外发送请求来执行签到。
编写一个 hooks 钩子,便于在多个题目详情页中复用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import { useEffect, useState } from "react" ;import { message } from "antd" ;import { addUserSignInUsingPost } from "@/api/userController" ;const useAddUserSignInRecord = ( const [loading, setLoading] = useState (false ); const doFetch = async ( setLoading (true ); try { await addUserSignInUsingPost (); } catch (e) { message.error ("添加刷题签到记录失败," + e.message ); } finally { setLoading (false ); } }; useEffect (() => { doFetch (); }, []); return { loading }; }; export default useAddUserSignInRecord;
注意,该钩子需要在客户端组件中执行,因为用到了 useEffect 防止重复请求、并且还需要获取到用户登录态。
可以在题目详情卡片 QuestionCard 这一客户端组件里使用钩子,这样所有题目详情页都会触发签到。代码如下:
1 2 3 4 5 6 7 8 const QuestionCard = (props: Props ) => { const { question } = props; useAddUserSignInRecord (); }
前端拓展
1)用户中心是否需要实现服务端渲染?如何实现服务端渲染?思路:先通过 userld 获取基础信息(未登录也可获取),再到客户端携带 Cookie 获取登录用户可见的信息。
2)用户中心页面添加权限校验 思路:可以通过 menu 菜单项配置,利用全局权限校验实现仅登录用户可见。
3)优化:如果前端签到成功,可以保存到LocalStorage 等位置,防止每次刷题都重复发送签到请求。
拓展 1、过期时间
问:Redis 中的 Bitmap 如何设置过期时间?需要设置一年的过期时间吗?答:如果用户有看往年记录的需求,可以用单次任务(或定时任务)将往年 Redis 数据落库,确保入库成功后,清理Redis 即可。
比如 2025 年1月1号,就可以将 2024 年的签到记录入库了。 除非是非常重要的数据,否则最好还是设置下过期时间,一年多即可。
再问:Bitmap 一年落库一次吗?不怕数据丢失吗?
答:Redis 本身有持久化机制,虽然无法完全保证数据不丢失,但是至少数据不会全部丢失。根据我们的刷题逻辑,即使Redis 意外宕机,丢失前几秒的部分签到,但是用户当天刷题后又会补回来。
如果想保证数据完全不丢失,那么需要在获取题目详情的时候,同步将刷题记录落库,这样性能相对而言就比较差,在一些重要的数据场景需要这样设计。或者再加一个消息队列来提高性能,但架构复杂度和系统维护成本就更高了。
2、更详细的刷题记录
分词题目搜索 方案设计
使用 Elasticsearch 实现题目数据的存储和分词搜索,需要将数据库的数据同步到 Elasticsearch。
1、什么是 ES
Elasticsearch 生态系统非常丰富,包含了一系列工具和功能,帮助用户处理、分析和可视化数据,Elastic Stack 是其核心组成部分。
2、ES 生态
Elasticsearch 生态系统非常丰富,包含了一系列工具和功能,帮助用户处理、分析和可视化数据,Elastic Stack 是其核心组成部分。
Elastic Stack(也称为 ELK Stack)由以下几部分组成:
Elasticsearch:核心搜索引擎,负责存储、索引和搜索数据。
Kibana:可视化平台,用于查询、分析和展示 Elasticsearch 中的数据。
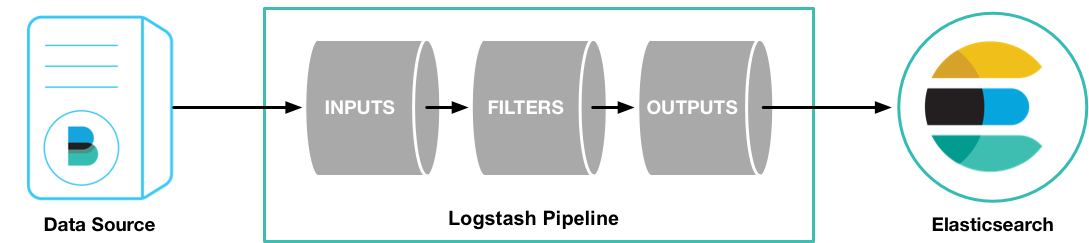
Logstash:数据处理管道,负责数据收集、过滤、增强和传输到 Elasticsearch。
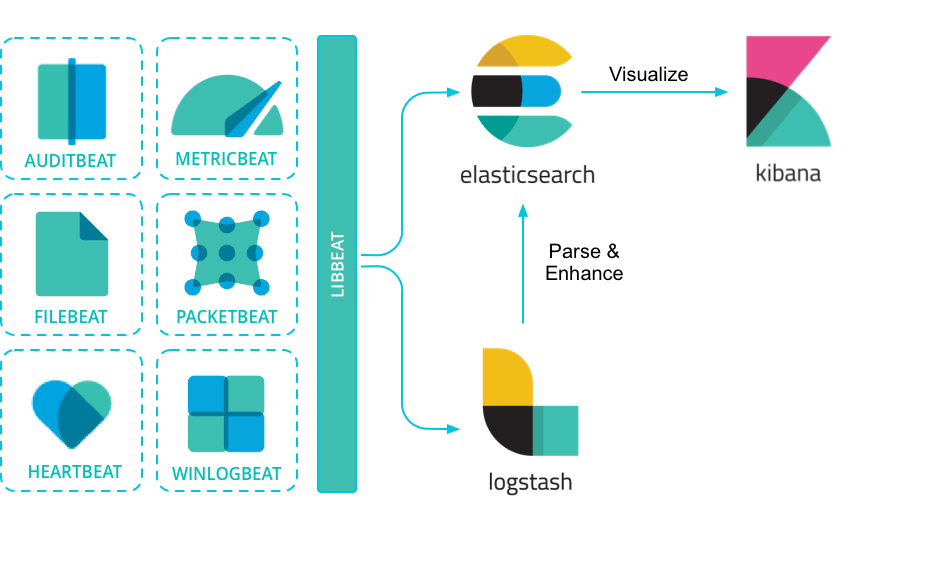
Beats:轻量级的数据传输工具,收集和发送数据到 Logstash 或 Elasticsearch。
Kibana 是 Elastic Stack 的可视化组件,允许用户通过图表、地图和仪表盘来展示存储在 Elasticsearch 中的数据。它提供了简单的查询接口、数据分析和实时监控功能。
Logstash 是一个强大的数据收集管道工具,能够从多个来源收集、过滤、转换数据,然后将数据发送到 Elasticsearch。Logstash 支持丰富的输入、过滤和输出插件。
Beats 是一组轻量级的数据采集代理,负责从不同来源收集数据并发送到 Elasticsearch 或 Logstash。常见的 Beats 包括:
Filebeat:收集日志文件。
Metricbeat:收集系统和服务的指标。
Packetbeat:监控网络流量。
3、Elasticsearch 的核心概念
索引(Index):类似于关系型数据库中的表,索引是数据存储和搜索的 基本单位 。每个索引可以存储多条文档数据。
文档(Document):索引中的每条记录,类似于数据库中的行。文档以 JSON 格式存储。
字段(Field):文档中的每个键值对,类似于数据库中的列。
映射(Mapping):用于定义 Elasticsearch 索引中文档字段的数据类型及其处理方式,类似于关系型数据库中的 Schema 表结构,帮助控制字段的存储、索引和查询行为。
集群(Cluster):多个节点组成的群集,用于存储数据并提供搜索功能。集群中的每个节点都可以处理数据。
分片(Shard):为了实现横向扩展,ES 将索引拆分成多个分片,每个分片可以分布在不同节点上。
副本(Replica):分片的复制品,用于提高可用性和容错性。
和数据库类比:
Elasticsearch 概念 关系型数据库类比
Index
Table
Document
Row
Field
Column
Mapping
Schema
Shard
Partition
Replica
Backup
4、Elasticsearch 实现全文检索的原理
1)分词:Elasticsearch 的分词器会将输入文本拆解成独立的词条(tokens),方便进行索引和搜索。分词的具体过程包括以下几步:
字符过滤:去除特殊字符、HTML 标签或进行其他文本清理。
分词:根据指定的分词器(analyzer),将文本按规则拆分成一个个词条。例如,英文可以按空格拆分,中文使用专门的分词器处理。
词汇过滤:对分词结果进行过滤,如去掉停用词(常见但无意义的词,如 “the”、”is” 等)或进行词形归并(如将动词变为原形)。
Elasticsearch 内置了很多分词器,比如按照空格分词等,默认只支持英文,可以在 官方文档 了解。
2)倒排索引:
倒排索引是 Elasticsearch 实现高效搜索的核心数据结构。它将文档中的词条映射到文档 ID,实现快速查找。
工作原理:
每个文档在被索引时,分词器会将文档内容拆解为多个词条。
然后,Elasticsearch 为每个词条生成一个倒排索引,记录该词条在哪些文档中出现。
举个例子,假设有两个文档:
中文分词后,生成的倒排索引大致如下:
词条
文档 ID
鱼皮
1, 2
是
1, 2
帅锅
1
好人
2
通过这种结构,查询某个词时,可以快速找到包含该词的所有文档。
5、Elasticsearch 打分规则
实际应用 Elasticsearch 来实现搜索功能时,我们不仅要求能搜到内容,而且还要把和用户搜索最相关的内容展示在前面。这就需要我们了解 Elasticsearch 的打分规则。
打分规则(Score)是用于衡量每个文档与查询条件的匹配度的评分机制。搜索结果的默认排序方式是按相关性得分( score)从高到低。Elasticsearch 使用 BM25 算法 来计算每个文档的得分,它是基于词频、反向文档频率、文档长度等因素来评估文档和查询的相关性。
打分的主要因素:
词频(TF, Term Frequency):查询词在文档中出现的次数,出现次数越多,得分越高。
反向文档频率(IDF, Inverse Document Frequency):查询词在所有文档中出现的频率。词在越少的文档中出现,IDF 值越高,得分越高。
文档长度:较短的文档往往被认为更相关,因为查询词在短文档中占的比例更大。
下面举一个例子:假设要在 Elasticsearch 中查询 鱼皮 这个关键词,索引中有以下三个文档:
文档 1:
1 2 3 plain 复制代码鱼皮是个帅小伙,鱼皮非常聪明,鱼皮很喜欢编程。
分析:
查询词 鱼皮 出现了 3 次。
该文档较短,查询词 鱼皮 的密度很高。
由于 鱼皮 在文档中多次出现且文档较短,因此得分较高,相关性较强。
文档 2:
分析:
尽管文档短,但是查询词出现的次数少,因此得分中等,相关性较普通。
文档 3:
1 2 3 plain 复制代码鱼皮是个帅小伙,他喜欢写代码。他的朋友们也很喜欢编程和技术讨论,大家经常一起参与各种技术会议,讨论分布式系统、机器学习和人工智能等主题。
分析:
查询词 鱼皮 出现了 1 次。
文档较长,且 鱼皮 只在文档开头出现,词条密度较低。
由于文档很长,鱼皮 出现的次数少,密度也低,因此得分较低,相关性不强。
再举个例子,什么是反向文档频率?
假如说 ES 中有 10 个文档,都包含了“鱼皮”这个关键词;只有 1 个文档包含了“帅锅”这个关键词。
现在用户搜索“鱼皮帅锅”,大概率会把后面这条文档搜出来,因为更稀有。
当然,以上只是简单举例,实际上 ES 计算打分规则时,会有一套较为复杂的公式,感兴趣的同学可以阅读下面资料来了解:
6、Elasticsearch 查询语法
Elasticsearch 支持多种查询语法,用于不同的场景和需求,主要包括查询 DSL、EQL、SQL 等。
*1)DSL 查询(* *Domain Specific Language* *) *
一种基于 JSON 的查询语言,它是 Elasticsearch 中最常用的查询方式。
示例:
1 2 3 4 5 6 7 json复制代码{ "query" : { "match" : { "message" : "Elasticsearch 是强大的" } } }
这个查询会对 message 字段进行分词,并查找包含 “Elasticsearch” 和 “强大” 词条的文档。
2)EQL
EQL 全称 Event Query Language,是一种用于检测和检索时间序列 事件 的查询语言,常用于日志和安全监控场景。
示例:查找特定事件
1 2 3 plain 复制代码process where process.name == "malware.exe"
这个查询会查找 process.name 为 “malware.exe” 的所有进程事件,常用于安全检测中的恶意软件分析。
3)SQL 查询
Elasticsearch 提供了类似于传统数据库的 SQL 查询语法,允许用户以 SQL 的形式查询 Elasticsearch 中的数据,对熟悉 SQL 的用户来说非常方便。
示例 SQL 查询:
1 2 3 sql 复制代码SELECT name, age FROM users WHERE age > 30 ORDER BY age DESC
这个查询会返回 users 索引中 age 大于 30 的所有用户,并按年龄降序排序。
以下几种简单了解即可:
4)Lucene 查询语法
Lucene 是 Elasticsearch 底层的搜索引擎,Elasticsearch 支持直接使用 Lucene 的查询语法,适合简单的字符串查询。
示例 Lucene 查询:
1 2 3 plain 复制代码name:Elasticsearch AND age:[30 TO 40]
这个查询会查找 name 字段为 “Elasticsearch” 且 age 在 30 到 40 之间的文档。
5)Kuery(KQL: Kibana Query Language)
KQL 是 Kibana 的查询语言,专门用于在 Kibana 界面上执行搜索查询,常用于仪表盘和数据探索中。
示例 KQL 查询:
1 2 3 plain 复制代码name: "Elasticsearch" and age > 30
这个查询会查找 name 为 “Elasticsearch” 且 age 大于 30 的文档。
6)Painless 脚本查询
Painless 是 Elasticsearch 的内置脚本语言,用于执行自定义的脚本操作,常用于排序、聚合或复杂计算场景。
示例 Painless 脚本:
1 2 3 4 5 6 7 8 9 10 11 12 json复制代码{ "query" : { "script_score" : { "query" : { "match" : { "message" : "Elasticsearch" } } , "script" : { "source" : "doc['popularity'].value * 2" } } } }
这个查询会基于 popularity 字段的值进行动态评分,将其乘以 2。
总结一下,DSL 是最通用的,EQL 和 KQL 则适用于特定场景,如日志分析和 Kibana 查询,而 SQL 则便于数据库开发人员上手。
7、Elasticsearch 查询条件
如何利用 Elasticsearch 实现数据筛选呢?需要了解其查询条件,以 ES 的 DSL 语法为例:
查询条件 介绍 示例 用途
match用于全文检索,将查询字符串进行分词并匹配文档中对应的字段。
{ "match": { "content": "鱼皮是帅小伙" } }适用于全文检索,分词后匹配文档内容。
term精确匹配查询,不进行分词。通常用于结构化数据的精确匹配,如数字、日期、关键词等。
{ "term": { "status": "active" } }适用于字段的精确匹配,如状态、ID、布尔值等。
terms匹配多个值中的任意一个,相当于多个 term 查询的组合。
{ "terms": { "status": ["active", "pending"] } }适用于多值匹配的场景。
range范围查询,常用于数字、日期字段,支持大于、小于、区间等查询。
{ "range": { "age": { "gte": 18, "lte": 30 } } }适用于数值或日期的范围查询。
bool组合查询,通过 must、should、must_not 等组合多个查询条件。
{ "bool": { "must": [ { "term": { "status": "active" } }, { "range": { "age": { "gte": 18 } } } ] } }适用于复杂的多条件查询,可以灵活组合。
wildcard通配符查询,支持 * 和 ?,前者匹配任意字符,后者匹配单个字符。
{ "wildcard": { "name": "鱼*" } }适用于部分匹配的查询,如模糊搜索。
prefix前缀查询,匹配以指定前缀开头的字段内容。
{ "prefix": { "name": "鱼" } }适用于查找以指定字符串开头的内容。
fuzzy模糊查询,允许指定程度的拼写错误或字符替换。
{ "fuzzy": { "name": "yupi~2" } }适用于处理拼写错误或不完全匹配的查询。
exists查询某字段是否存在。
{ "exists": { "field": "name" } }适用于查找字段存在或缺失的文档。
match_phrase短语匹配查询,要求查询的词语按顺序完全匹配。
{ "match_phrase": { "content": "鱼皮 帅小伙" } }适用于严格的短语匹配,词语顺序和距离都严格控制。
match_all匹配所有文档。
{ "match_all": {} }适用于查询所有文档,通常与分页配合使用。
ids基于文档 ID 查询,支持查询特定 ID 的文档。
{ "ids": { "values": ["1", "2", "3"] } }适用于根据文档 ID 查找特定文档。
geo_distance地理位置查询,基于地理坐标和指定距离查询。
{ "geo_distance": { "distance": "12km", "location": { "lat": 40.73, "lon": -74.1 } } }适用于根据距离计算查找地理位置附近的文档。
aggregations聚合查询,用于统计、计算和分组查询,类似 SQL 中的 GROUP BY。
{ "aggs": { "age_stats": { "stats": { "field": "age" } } } }适用于统计和分析数据,比如求和、平均值、最大值等。
其中的几个关键:
精确匹配 vs. 全文检索:term 是精确匹配,不分词;match 用于全文检索,会对查询词进行分词。
组合查询:bool 查询可以灵活组合多个条件,适用于复杂的查询需求。
模糊查询:fuzzy 和 wildcard 提供了灵活的模糊匹配方式,适用于拼写错误或不完全匹配的场景。
了解上面这些一般就足够了,更多可以随用随查,参考 官方文档 。
8、Elasticsearch 客户端
前面了解了 Elasticsearch 的概念和查询语法,但是如何执行 Elasticsearch 操作呢?还需要了解下 ES 的客户端,列举一些常用的:
1)HTTP API:Elasticsearch 提供了 RESTful HTTP API,用户可以通过直接发送 HTTP 请求来执行索引、搜索和管理集群的操作。官方文档
2)Kibana:Kibana 是 Elasticsearch 官方提供的可视化工具,用户可以通过 Kibana 控制台使用查询语法(如 DSL、KQL)来执行搜索、分析和数据可视化。
3)Java REST Client:Elasticsearch 官方提供的 Java 高级 REST 客户端库,用于 Java 程序中与 Elasticsearch 进行通信,支持索引、查询、集群管理等操作。官方文档
4)Spring Data Elasticsearch:Spring 全家桶的一员,用于将 Elasticsearch 与 Spring 框架集成,通过简化的 Repository 方式进行索引、查询和数据管理操作。官方文档
5)Elasticsearch SQL CLI:命令行工具,允许通过类 SQL 语法直接在命令行中查询 Elasticsearch 数据,适用于熟悉 SQL 的用户。
此外,Elasticsearch 当然不只有 Java 的客户端,Python、PHP、Node.js、Go 的客户端都是支持的。
💡 在选择客户端时,要格外注意版本号!!!要跟 Elasticsearch 的版本保持兼容。
9、ES 数据同步方案
一般情况下,如果做查询搜索功能,使用 ES 来模糊搜索,但是数据是存放在数据库 MySQL 里的,所以说我们需要把 MySQL 中的数据和 ES 进行同步,保证数据一致(以 MySQL 为主)。
数据流向:MySQL => ES (单向)
数据同步一般有 2 个过程:全量同步(首次)+ 增量同步(新数据)
总共有 4 种主流方案:
1)定时任务
比如 1 分钟 1 次,找到 MySQL 中过去几分钟内(至少是定时周期的 2 倍)发生改变的数据,然后更新到 ES。
优点:
简单易懂,开发、部署、维护相对容易。
占用资源少,不需要引入复杂的第三方中间件。
不用处理复杂的并发和实时性问题。
缺点:
有时间差 :无法做到实时同步,数据存在滞后。数据频繁变化时,无法确保数据完全同步,容易出现错过更新的情况。
对大数据量的更新处理不够高效,可能会引入重复更新逻辑。
应用场景:
数据实时性要求不高:适合数据短时间内不同步不会带来重大影响的场景。
数据基本不发生修改:适合数据几乎不修改、修改不频繁的场景。
数据容忍丢失
2)双写
写数据的时候,必须也去写 ES;更新删除数据库同理。
可以通过事务保证数据一致性,使用事务时,要先保证 MySQL 写成功,因为如果 ES 写入失败了,不会触发回滚,但是可以通过定时任务 + 日志 + 告警进行检测和修复(补偿)。
优点:
方案简单易懂,业务逻辑直接控制数据同步。
可以利用事务部分保证 MySQL 和 ES 的数据一致性。
同步的时延较短,理论上可以接近实时更新 ES。
缺点:
影响性能 :每次写 MySQL 时,需要同时操作 ES,增加了业务写入延迟,影响性能。一致性问题 :如果 ES 写入失败,MySQL 事务提交成功后,ES 可能会丢失数据;或者 ES 写入成功,MySQL 事务提交失败,ES 无法回滚。因此必须额外设计监控、补偿机制来检测同步失败的情况(如通过定时任务、日志和告警修复)。代码复杂度增加,需要对每个写操作都进行双写处理。
应用场景:
实时性要求较高
业务写入频率较低:适合写操作不频繁的场景,这样对性能的影响较小。
3)用 Logstash 数据同步管道
一般要配合 kafka 消息队列 + beats 采集器:
优点:
配置驱动 :基于配置文件,减少了手动编码,数据同步逻辑和业务代码解耦。扩展性好 :可以灵活引入 Kafka 等消息队列实现异步数据同步,并可处理高吞吐量数据。支持多种数据源:Logstash 支持丰富的数据源,方便扩展其他同步需求。
缺点:
灵活性差 :需要通过配置文件进行同步,复杂的业务逻辑可能难以在配置中实现,无法处理细粒度的定制化需求。引入额外组件,维护成本高:通常需要引入 Kafka、Beats 等第三方组件,增加了系统的复杂性和运维成本。
应用场景:
大数据同步 :适合大规模、分布式数据同步场景。对实时性要求不高 :适合数据流处理或延迟容忍较大的系统。系统已有 Kafka 或类似的消息队列架构:如果系统中已经使用了 Kafka 等中间件,使用 Logstash 管道会变得很方便。
4)监听 MySQL Binlog
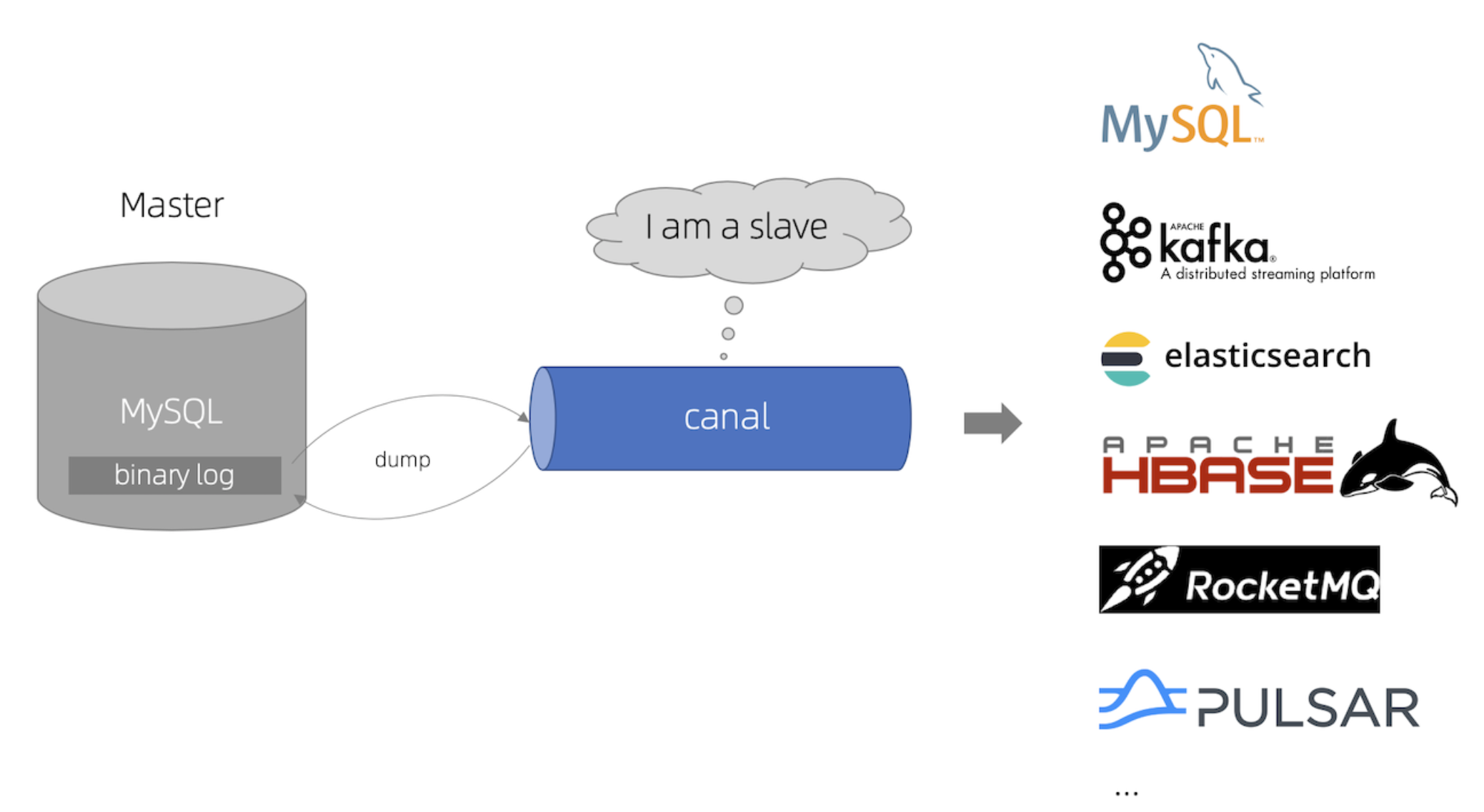
有任何数据变更时都能够实时监听到,并且同步到 Elasticsearch。一般不需要自己监听,可以使用现成的技术,比如 Canal 。
💡 Canal 的核心原理:数据库每次修改时,会修改 binlog 文件,只要监听该文件的修改,就能第一时间得到消息并处理
优点:
实时性强 :能够在 MySQL 数据发生变更的第一时间同步到 ES,做到真正的实时同步。轻量级:Binlog 是数据库自带的日志功能,不需要修改核心业务代码,只需要新增监听逻辑。
缺点:
引入外部依赖:需要引入像 Canal 这样的中间件,增加了系统的复杂性和维护成本。
运维难度增加:需要确保 Canal 或者其他 Binlog 监听器的稳定运行,并且对 MySQL 的 Binlog 配置要求较高。
一致性问题:如果 Canal 服务出现问题或暂停,数据可能会滞后或丢失,必须设计补偿机制。
应用场景:
实时同步要求高 :适合需要实时数据同步的场景,通常用于高并发、高数据一致性要求的系统。数据频繁变化 :适合数据变更频繁且需要高效增量同步的场景。
最终方案:对于本项目,由于数据量不大,题目更新也不频繁,容忍丢失和不一致,所以选用方案一,实现成本最低。
后端开发(ES 实战) 1、Elasticsearch 搭建 目标:安装 Elasticsearch 和 Kibana,能够在 Kibana 查看到 Elasticsearch 存储的数据。
💡 也可以直接使用云 Elasticsearch 服务,省去自主搭建的时间,推荐使用 Serverless 版本,学完关掉就行。
Elasticsearch 更新迭代非常快,所以安装时,一定要注意慎重选择版本号!
由于我们自己的项目用的 Spring Boot 2.7.6 版本,对应的 Spring Data Elasticsearch 客户端版本是 4.x,支持的 Elasticsearch 是 7.x,所以建议 Elasticsearch 使用 7.x 的版本。
安装版本为 7.17.24
💡 可以在 官方文档 了解到版本兼容情况:比如 Spring 6 才支持 Elasticsearch 8.x
1)安装 Elasticsearch(9200 端口) 参考官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/setup.html
Windows 解压安装:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/zip-windows.html
其他操作系统安装:https://www.elastic.co/guide/en/elasticsearch/reference/7.17/targz.html
如果官网下不动,可以用鱼皮已经下载好的:https://pan.baidu.com/s/1u73-Nlolrs8Rzb1_b6X6HA ,提取码:c2sd
注意,安装路径不要包含中文!
安装完成后进入 es 目录并执行启动命令(或者进入 bin 目录点击运行 elasticsearch.bat 程序):
可以用 CURL 测试是否启动成功:
1 复制代码curl -X GET "localhost:9200/?pretty"
2)安装 Kibana(5601 端口) 注意,只要是同一套技术,所有版本必须一致!此处都用 7.17 版本!
参考官方文档:https://www.elastic.co/guide/en/kibana/7.17/introduction.html
安装 Kibana:https://www.elastic.co/guide/en/kibana/7.17/install.html
安装完成后进入 kibana 目录并执行启动命令:
正常输出如图:
访问 http://localhost:5601/,即可开始使用。
配置中文界面
但 kibana 默认是英文,不变阅读,可以修改 config/kibana.yml 中的国际化配置:
然后重启 kibana 即可。
注意,目前 Kibana 面板没有增加权限校验,所有人都能访问,所以请勿在线上直接部署!
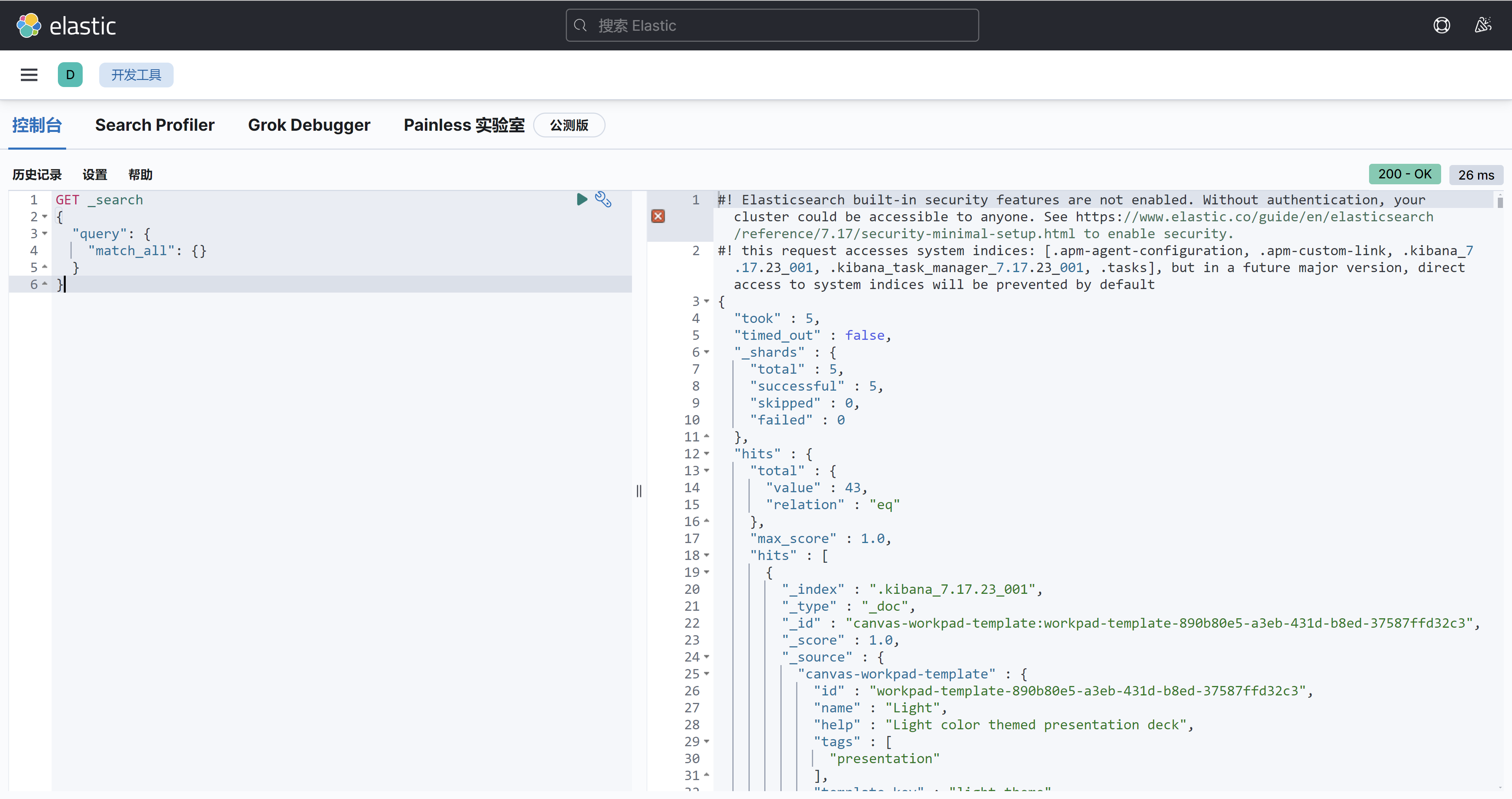
3)测试 尝试利用 Kibana 的开发工具来操作 Elasticsearch 的数据,比如查询:
验证下分词器的效果,比如使用标准分词器:
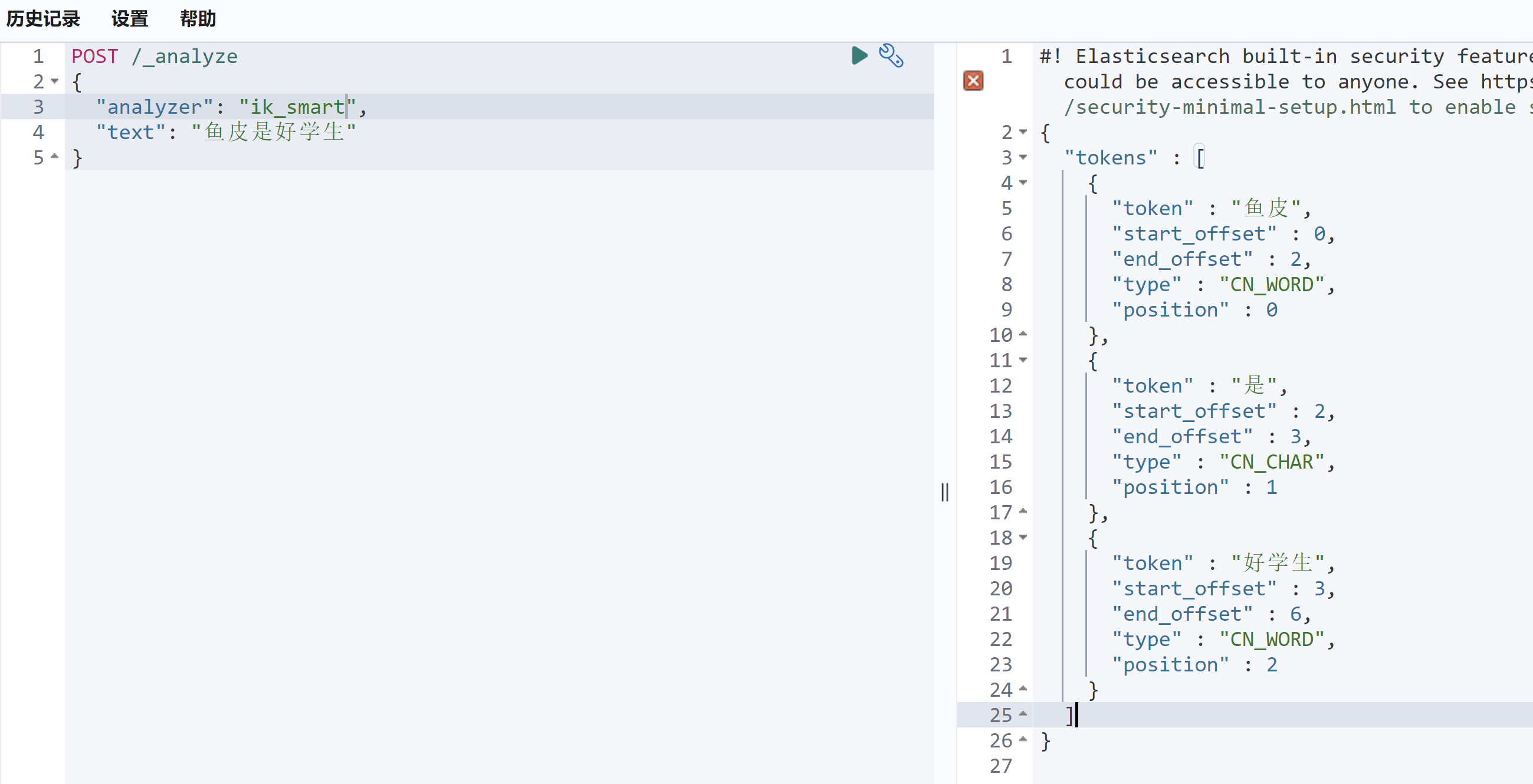
1 2 3 4 5 POST /_analyze { "analyzer" : "standard" , "text" : "鱼皮是个帅小伙,非常喜欢编程" }
效果如图,英文被识别为了一个词,但中文未被识别:
默认支持的分词器如下:
standard:标准分词器。
simple:简单分词器。
whitespace:按空格分词。
stop:带停用词的分词器。
keyword:不分词,将整个字段作为一个词条。
pattern:基于正则表达式的分词器。
ngram 和 edge_ngram:n-gram 分词器。
由于这些分词器都不支持中文,所以需要安装 IK 中文分词器,以满足我们的业务需要。
4)安装 IK 中文分词器(ES 插件) 开源地址:https://github.com/medcl/elasticsearch-analysis-ik
直接按照官方指引安装即可,注意下载和我们 Elasticsearch 一致的版本,可以在这里找到各版本的插件包:https://release.infinilabs.com/analysis-ik/stable/
在 ES 安装目录下执行:
1 .\bin\elasticsearch-plugin.bat install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.17.24.zip
安装成功,需要重启 ES:
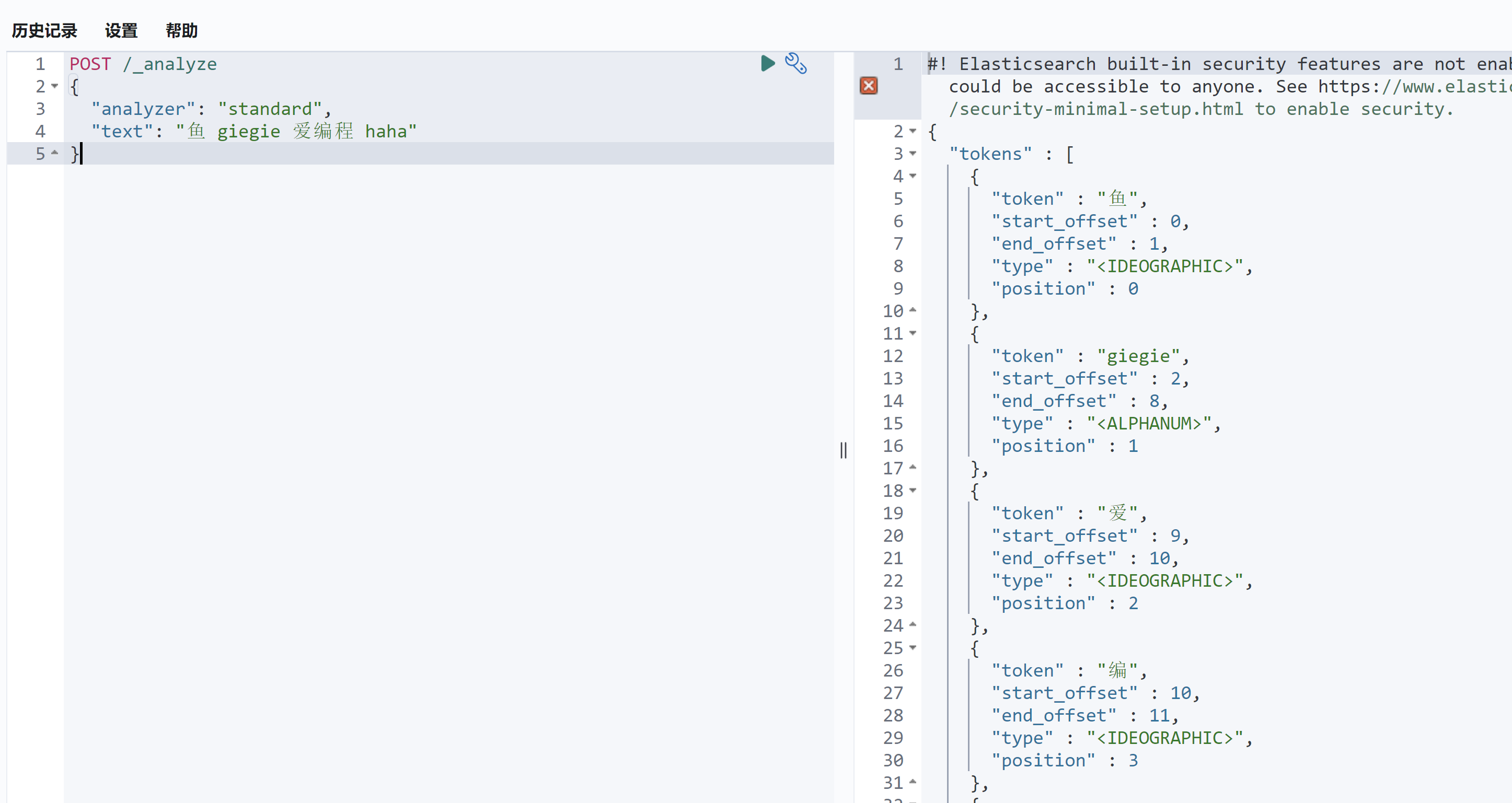
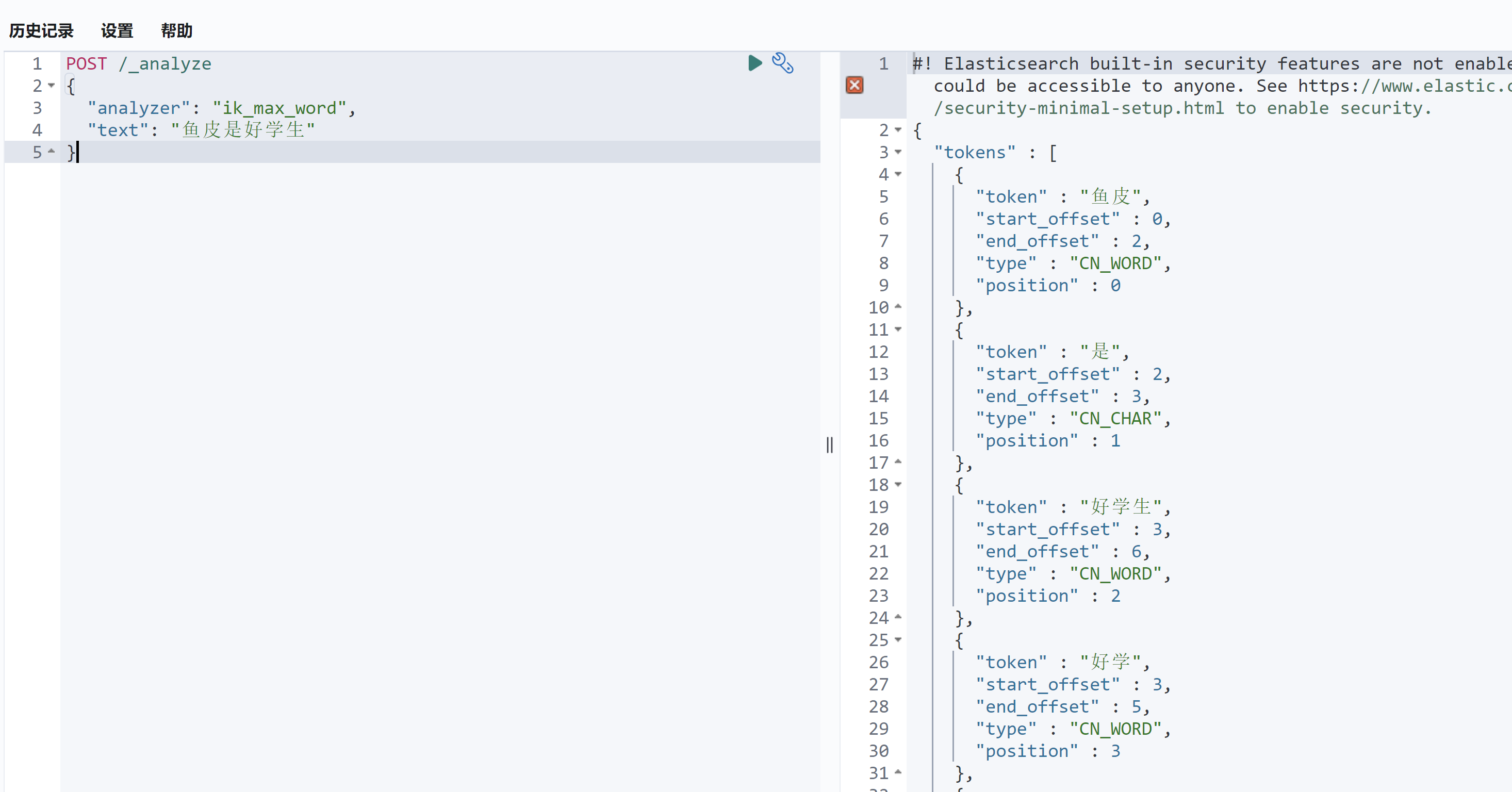
IK 分词器插件为我们提供了两个分词器:ik_smart 和 ik_max_word。
ik_smart 是智能分词 ,尽量选择最像一个词的拆分方式,比如“好学生”会被识别为一个词
ik_max_word 尽可能地分词 ,可以包括组合词,比如“好学生”会被识别为 3 个词:好学生、好学、学生
测试一下:
1 2 3 4 5 POST /_analyze { "analyzer": "ik_smart", "text": "鱼皮是好学生" }
如图:
这两种分词器如何选用呢?其实可以结合:
ik_smart:适用于 搜索分词 ,即在查询时使用,保证性能的同时提供合理的分词精度。ik_max_word:适用于 底层索引分词 ,确保在建立索引时尽可能多地分词,提高查询时的匹配度和覆盖面。
下面就来实战下 ES 索引的设计吧~
💡 思考:有些时候 IK 识别词汇不准,比如不认识“程序员鱼皮”,怎么样让 IK 按自己的规则分词?
解决方案:插件支持自定义词典。可以按照 官方文档 配置。
2、设计 ES 索引 为了将 MySQL 题目表数据导入到 Elasticsearch 中并实现分词搜索,需要为 ES 索引定义 mapping。ES 的 mapping 用于定义字段的类型、分词器及其索引方式。
相当于数据库的建表,数据库建表时我们要考虑索引,同样 Elasticsearch 建立索引时,要考虑到字段选取、分词器、字段格式等问题。
基于我们数据库的表结构和需求,我们可以定义 title、content、answer 等字段使用分词搜索,同时为其他字段指定适当的类型。以下是本项目的 mapping 定义:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 { "mappings" : { "properties" : { "title" : { "type" : "text" , "analyzer" : "ik_max_word" , "search_analyzer" : "ik_smart" , "fields" : { "keyword" : { "type" : "keyword" , "ignore_above" : 256 } } } , "content" : { "type" : "text" , "analyzer" : "ik_max_word" , "search_analyzer" : "ik_smart" } , "tags" : { "type" : "keyword" } , "answer" : { "type" : "text" , "analyzer" : "ik_max_word" , "search_analyzer" : "ik_smart" } , "userId" : { "type" : "long" } , "editTime" : { "type" : "date" , "format" : "yyyy-MM-dd HH:mm:ss" } , "createTime" : { "type" : "date" , "format" : "yyyy-MM-dd HH:mm:ss" } , "updateTime" : { "type" : "date" , "format" : "yyyy-MM-dd HH:mm:ss" } , "isDelete" : { "type" : "keyword" } } } }
为什么不显示指定 id 字段?
在 Elasticsearch 中,每个文档都有一个唯一的 _id 字段来标识文档,该字段用于文档的主键索引和唯一标识。通常,开发者并不需要显式定义 id 字段,因为 Elasticsearch 会自动生成 _id,或者在插入数据时,你可以手动指定 _id。
由于 _id 是 Elasticsearch 内部的系统字段,它默认存在并作为主键使用,因此在 mappings 中通常不需要显式定义。如果你想让某个字段(如 userId 或其他唯一标识)作为 _id,可以在插入文档时指定该字段的值作为 _id。比如:
1 2 3 4 5 PUT /index/_doc/<custom_id> { "userId" : 1001, "title" : "Example" }
日期字段为什么要格式化?
日期字段的格式化(format: "yyyy-MM-dd HH:mm:ss")有以下几个考虑:
一致性:定义日期字段的格式可以确保所有插入的日期数据都是一致的,避免因不同的日期格式导致解析错误。例如,Elasticsearch 默认可以支持多种日期格式,但如果不定义明确的格式,可能会导致不一致的日期解析。
优化查询:格式化日期后,Elasticsearch 知道该如何存储和索引这些时间数据,从而可以高效地执行基于日期的范围查询、过滤和排序操作。明确的格式定义还可以帮助 Elasticsearch 进行更优化的存储和压缩。
避免歧义:没有明确格式的日期可能导致歧义,比如 "2023-09-03" 是日期,还是年份?加上时间部分(如 "yyyy-MM-dd HH:mm:ss")可以更明确地表明时间的精度,便于进行更精确的查询。
tags 支持数组么?为什么
在 Elasticsearch 中,所有的字段类型(包括 keyword 和 text)默认都支持数组。你可以直接插入一个包含多个值的数组,Elasticsearch 会自动将其视为多个值的集合。例如,以下文档中,tags 字段是一个数组:
1 2 3 4 { "title" : "How to learn Elasticsearch" , "tags" : [ "Elasticsearch" , "Search" , "Database" ] }
在查询时,Elasticsearch 会将数组中的每个值视为独立的 keyword,可以进行精确匹配。
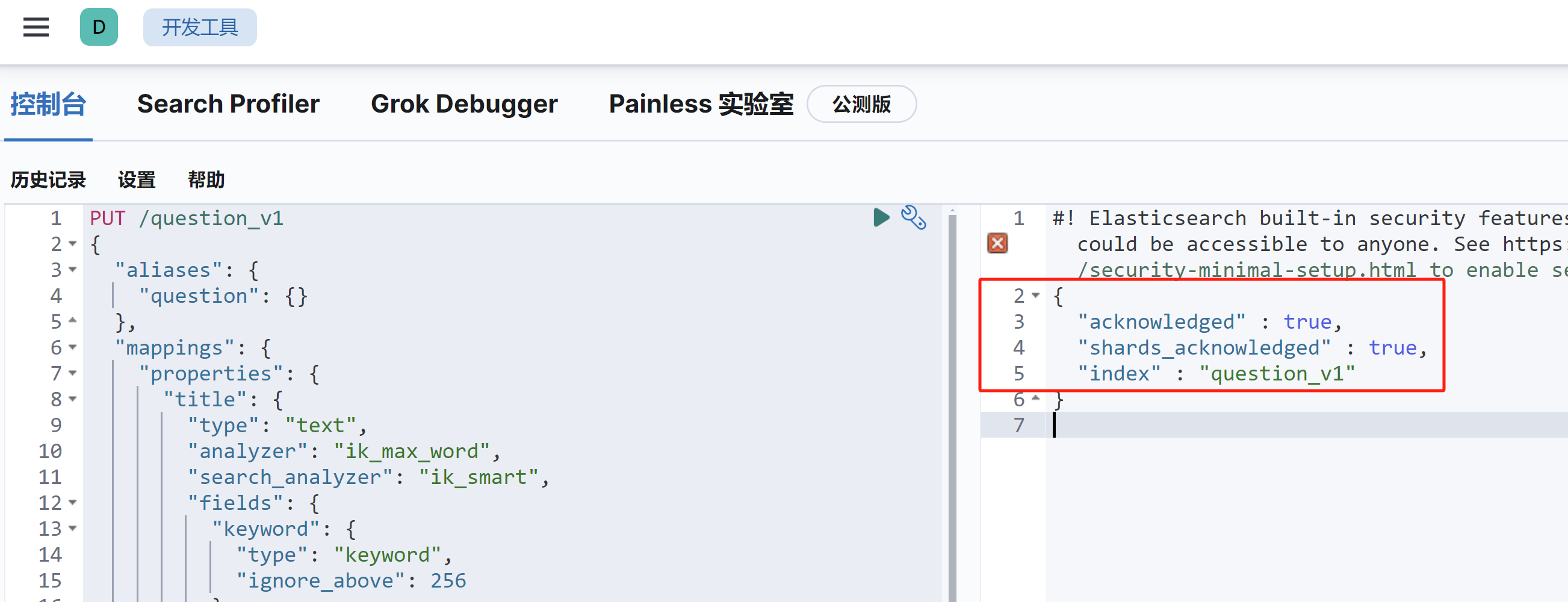
3、新建索引 可以通过如下命令创建索引,在 Kibana 开发者工具中执行、或者用 CURL 调用 Elasticsearch 执行均可:可以通过如下命令创建索引,在 Kibana 开发者工具中执行、或者用 CURL 调用 Elasticsearch 执行均可:
1 2 3 4 5 6 7 8 PUT /question_v1 { "mappings" : { "properties" : { ... } } }
但是有一点要注意,推荐在创建索引时添加 alias(别名) ,因为它提供了灵活性和简化索引管理的能力。具体原因如下:
零停机切换索引:在更新索引或重新索引数据时,你可以创建一个新索引并使用 alias 切换到新索引,而不需要修改客户端查询代码,避免停机或中断服务。
简化查询:通过 alias,可以使用一个统一的名称进行查询,而不需要记住具体的索引名称(尤其当索引有版本号或时间戳时)。
索引分组:alias 可以指向多个索引,方便对多个索引进行联合查询,例如用于跨时间段的日志查询或数据归档。
其中,第一个是重点,举个例子,在创建索引时添加 alias:
1 2 3 4 5 6 PUT /my_index_v1 { "aliases": { "my_index": {} } }
这个 alias 可以在后续版本中指向新的索引(如 my_index_v2),无需更改查询逻辑,查询时仍然使用 my_index。
所以,我们要执行的完整命令如下,可以放到后端项目目录中进行备份:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 PUT /question_v1 { "aliases": { "question": {} }, "mappings": { "properties": { "title": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "content": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "tags": { "type": "keyword" }, "answer": { "type": "text", "analyzer": "ik_max_word", "search_analyzer": "ik_smart" }, "userId": { "type": "long" }, "editTime": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, "createTime": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, "updateTime": { "type": "date", "format": "yyyy-MM-dd HH:mm:ss" }, "isDelete": { "type": "keyword" } } } }
执行以上命令创建索引,创建成功的样子如下所示 :
4、引入 ES 客户端 1)引入依赖
1 2 3 4 5 <dependency > <groupId > org.springframework.boot</groupId > <artifactId > spring-boot-starter-data-elasticsearch</artifactId > </dependency >
2)更改 yml 配置
1 2 3 4 elasticsearch: uris: http://localhost:9200 username: root password: 123456
3)使用 spring data es 提供的 Bean 即可操作 Bean,可以直接通过 @Resource 注解注入
1 2 @Resource private ElasticsearchRestTemplate elasticsearchRestTemplate;
4)编写一个单元测试文件,验证对于 Elasticsearch 的增删改查基本操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 @SpringBootTest public class ElasticsearchRestTemplateTest { @Autowired private ElasticsearchRestTemplate elasticsearchRestTemplate; private final String INDEX_NAME = "test_index" ; @Test public void indexDocument () { Map<String, Object> doc = new HashMap <>(); doc.put("title" , "Elasticsearch Introduction" ); doc.put("content" , "Learn Elasticsearch basics and advanced usage." ); doc.put("tags" , "elasticsearch,search" ); doc.put("answer" , "Yes" ); doc.put("userId" , 1L ); doc.put("editTime" , "2023-09-01 10:00:00" ); doc.put("createTime" , "2023-09-01 09:00:00" ); doc.put("updateTime" , "2023-09-01 09:10:00" ); doc.put("isDelete" , false ); IndexQuery indexQuery = new IndexQueryBuilder ().withId("1" ).withObject(doc).build(); String documentId = elasticsearchRestTemplate.index(indexQuery, IndexCoordinates.of(INDEX_NAME)); assertThat(documentId).isNotNull(); } @Test public void getDocument () { String documentId = "1" ; Map<String, Object> document = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME)); assertThat(document).isNotNull(); assertThat(document.get("title" )).isEqualTo("Elasticsearch Introduction" ); } @Test public void updateDocument () { String documentId = "1" ; Map<String, Object> updates = new HashMap <>(); updates.put("title" , "Updated Elasticsearch Title" ); updates.put("updateTime" , "2023-09-01 10:30:00" ); UpdateQuery updateQuery = UpdateQuery.builder(documentId) .withDocument(Document.from(updates)) .build(); elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of(INDEX_NAME)); Map<String, Object> updatedDocument = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME)); assertThat(updatedDocument.get("title" )).isEqualTo("Updated Elasticsearch Title" ); } @Test public void deleteDocument () { String documentId = "1" ; String result = elasticsearchRestTemplate.delete(documentId, IndexCoordinates.of(INDEX_NAME)); assertThat(result).isNotNull(); } @Test public void deleteIndex () { IndexOperations indexOps = elasticsearchRestTemplate.indexOps(IndexCoordinates.of(INDEX_NAME)); boolean deleted = indexOps.delete(); assertThat(deleted).isTrue(); } }
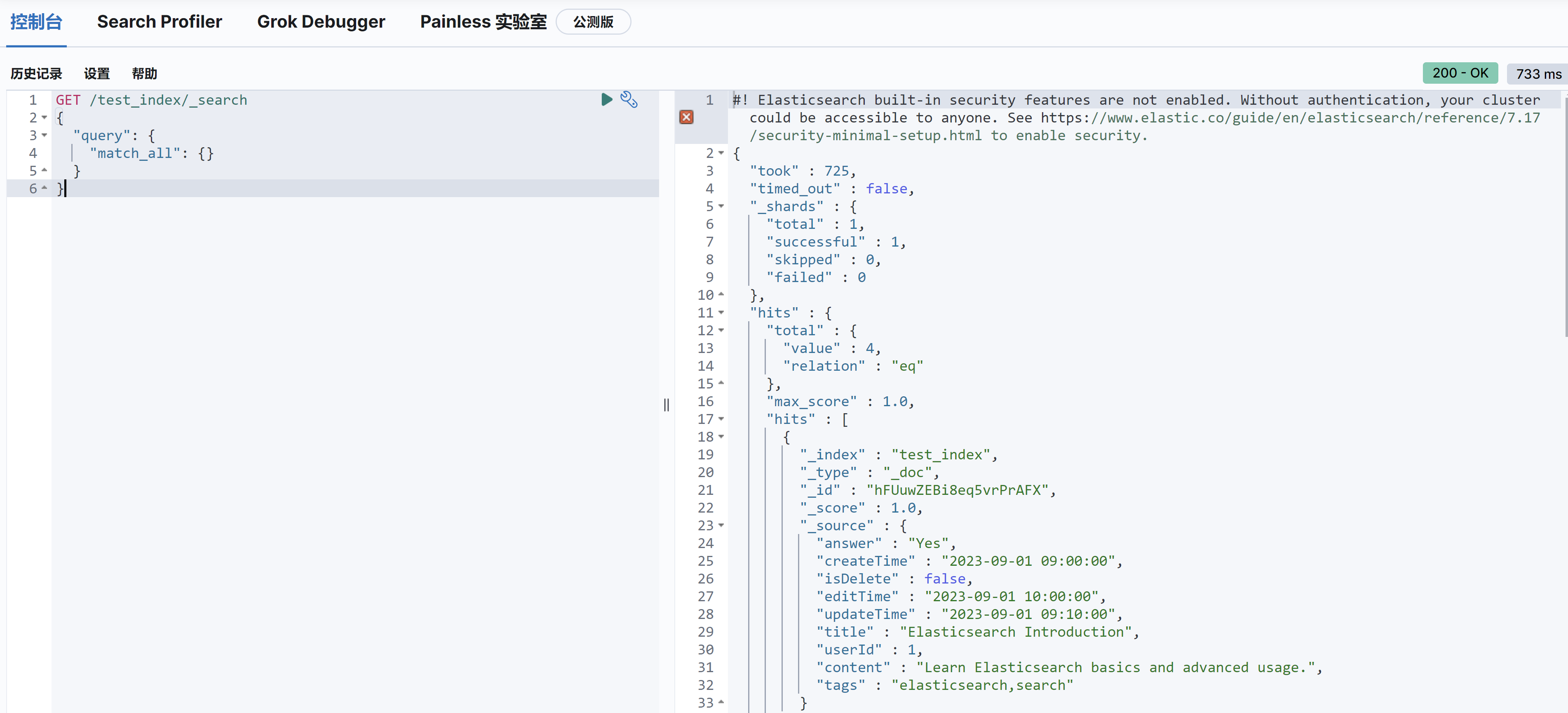
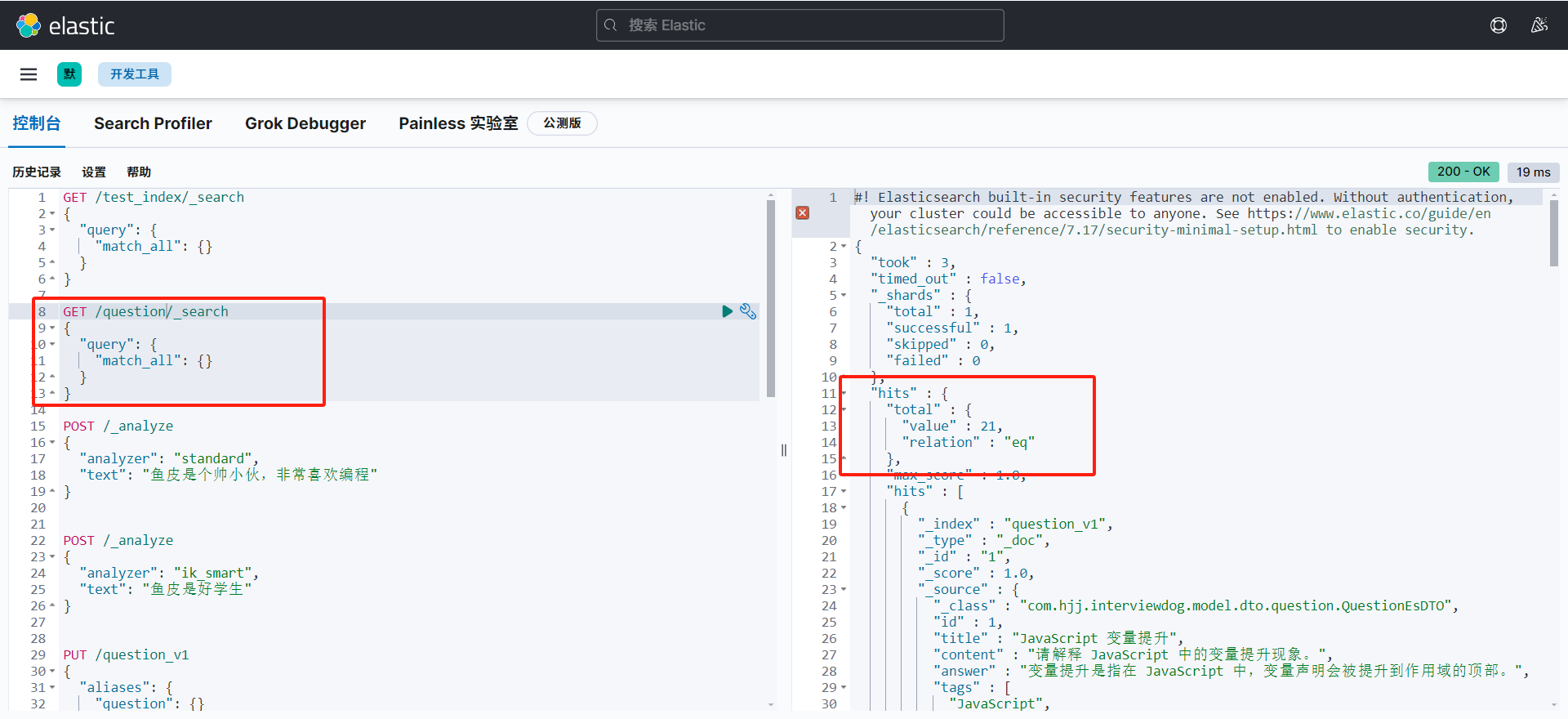
可以用 kibana 开发者工具查看数据情况:
1 2 3 4 5 6 GET /test_index/_search { "query": { "match_all": {} } }
查出的数据如下所示:
几个注意事项:
当你向一个不存在的索引中插入数据时,Elasticsearch 会根据文档内容自动推断字段类型,并为这些字段创建映射。这就是 ES 的 动态映射 (Dynamic Mapping)功能。然而,这种自动生成的映射有一些局限性,可能导致字段类型不够规范。
ES 中,_开头的字段表示系统默认字段,比如 _id,如果系统不指定,会自动生成。但是不会在 _source 字段中补充 id 的值,所以建议大家手动指定,让数据更完整。
ES 插入和更新数据没有 MySQL 那么严格,尤其是在动态 Mapping 模式下,只要指定了相同的文档 id,ES 允许动态添加字段和更新文档。
ES 中下划线开头的代表是默认字段,凡是默认字段都不用明确指定。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 { "took" : 8, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 1, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "test_index", "_type" : "_doc", "_id" : "1", "_score" : 1.0, "_source" : { "answer" : "Yes", "createTime" : "2023-09-01 09:00:00", "isDelete" : false, "editTime" : "2023-09-01 10:00:00", "updateTime" : "2023-09-01 10:30:00", "title" : "Updated Elasticsearch Title", "userId" : 1, "content" : "Learn Elasticsearch basics and advanced usage.", "tags" : "elasticsearch,search" } } ] } }
source 代表是真正的数据,而 _id 代表文档的 id,我们最好在插入数据时指定真正数据的 id
总结
通过这个单元测试,我们也能基本了解 Spring Data Elasticsearch 操作 ES 的方法:
构造一个 Query 对象,比如插入数据使用 IndexQuery,更新数据使用 UpdateQuery
调用 elasticsearchRestTemplate 的增删改查方法,传入 Query 对象和要操作的索引作为参数
对返回值进行处理
实例代码如下:
1 2 3 4 5 6 7 8 9 10 11 Map<String, Object> updates = new HashMap <>(); updates.put("title" , "Updated Elasticsearch Title" ); updates.put("updateTime" , "2023-09-01 10:30:00" ); UpdateQuery updateQuery = UpdateQuery.builder(documentId) .withDocument(Document.from(updates)) .build(); elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of(INDEX_NAME)); Map<String, Object> updatedDocument = elasticsearchRestTemplate.get(documentId, Map.class, IndexCoordinates.of(INDEX_NAME));
但是有个问题就是,上述代码都是用 Map 传递数据,不像在 MyBatis 中利用实例类传递参数。当然 Spring Data ES 也支持这种方法来传递参数
5、编写 ES Dao 层 1)在 model.dto.question 包中定义和 ES 对应的实体类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 @Document(indexName = "question") @Data public class QuestionEsDTO implements Serializable { private static final String DATE_TIME_PATTERN = "yyyy-MM-dd HH:mm:ss" ; @Id private Long id; private String title; private String content; private String answer; private List<String> tags; private Long userId; @Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN) private Date createTime; @Field(type = FieldType.Date, format = {}, pattern = DATE_TIME_PATTERN) private Date updateTime; private Integer isDelete; private static final long serialVersionUID = 1L ; public static QuestionEsDTO objToDto (Question question) { if (question == null ) { return null ; } QuestionEsDTO questionEsDTO = new QuestionEsDTO (); BeanUtils.copyProperties(question, questionEsDTO); String tagsStr = question.getTags(); if (StringUtils.isNotBlank(tagsStr)) { questionEsDTO.setTags(JSONUtil.toList(tagsStr, String.class)); } return questionEsDTO; } public static Question dtoToObj (QuestionEsDTO questionEsDTO) { if (questionEsDTO == null ) { return null ; } Question question = new Question (); BeanUtils.copyProperties(questionEsDTO, question); List<String> tagList = questionEsDTO.getTags(); if (CollUtil.isNotEmpty(tagList)) { question.setTags(JSONUtil.toJsonStr(tagList)); } return question; } }
2)定义 Dao 层
可以在 esdao 包中统一存放对 Elasticsearch 的操作,只需要继承 ElasticsearchRepository 类即可。
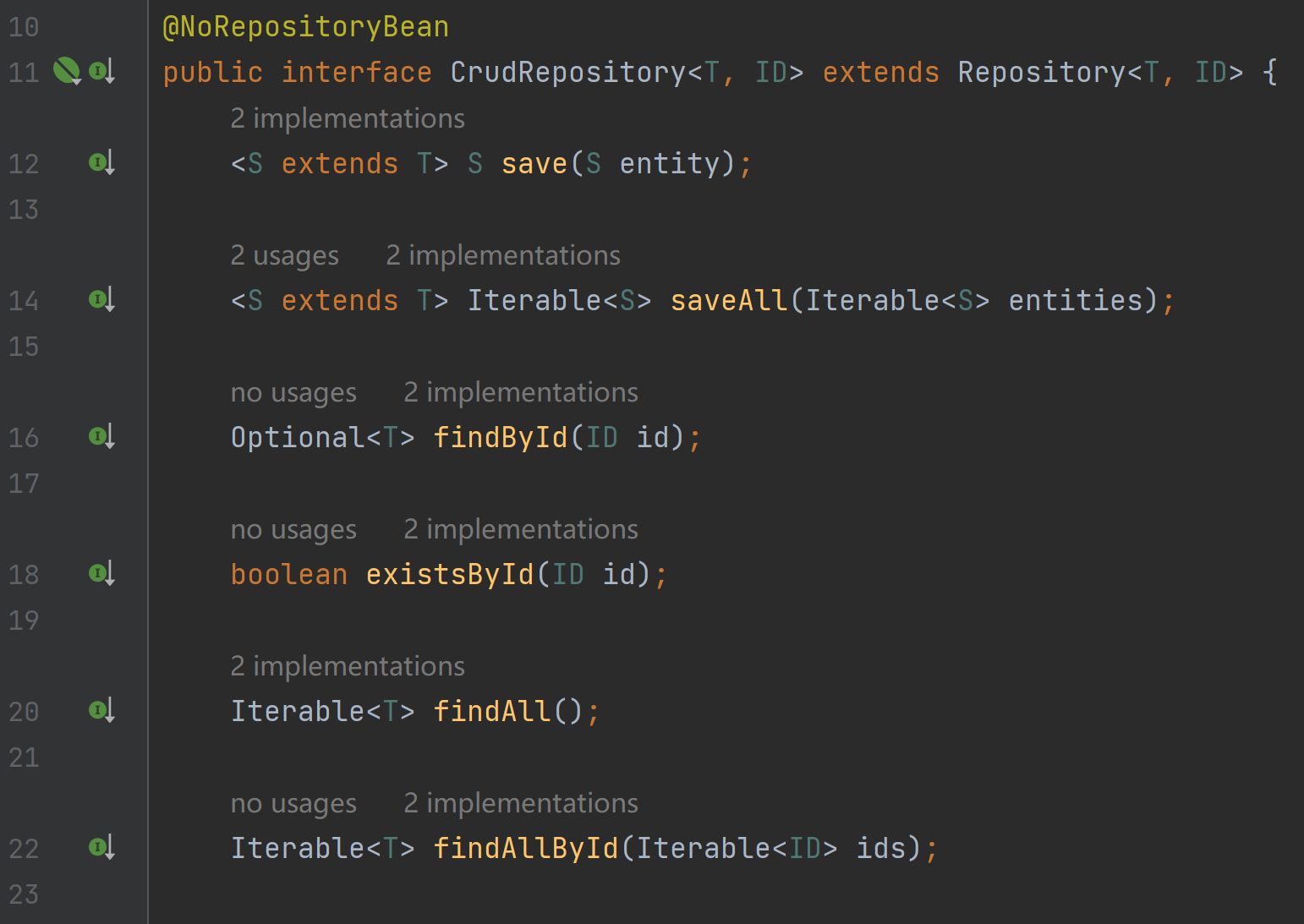
1 2 3 4 5 6 7 public interface QuestionEsDao extends ElasticsearchRepository <QuestionEsDTO, Long> { }
仔细了解后可以知道 ElasticsearchRepository 类为我们提供了大量现成的 CRUD 操作:
而且还支持根据方法名自动映射为查询操作,比如在 QuestionEsDao 中定义下列方法,就会自动根据 userId 查询数据。
1 2 3 4 5 6 List<QuestionEsDTO> findByUserId (Long userId) ;
编写一个测试类来验证下:
1 2 3 4 5 6 7 8 9 10 11 @SpringBootTest class QuestionEsDaoTest { @Resource private QuestionEsDao questionEsDao; @Test void findByUserId () { questionEsDao.findByUserId(1L ); } }
两种操作 ES 的方法,根据业务需求进行选择:
第 1 种方式:Spring 默认给我们提供的操作 es 的客户端对象 ElasticsearchRestTemplate,也提供了增删改查,它的增删改查更灵活,适用于更复杂的操作 ,返回结果更完整,但需要自己解析。
第 2 种方式:ElasticsearchRepository<Entity, IdType>,默认提供了更简单易用的增删改查,返回结果也更直接。适用于可预期的、相对简单的操作 。
6、如何向 ES 写入全量数据 可以通过编写单次执行的任务,将 MySQL 中题目表的数据,全量写入到 Elasticsearch。
可以通过实现 CommandLineRunner 接口定义单次任务,也可以编写一个仅管理员可用的接口,根据需要选择就好。
在 job/once 目录下编写任务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @Component @Slf4j public class FullSyncQuestionToEs implements CommandLineRunner { @Resource private QuestionService questionService; @Resource private QuestionEsDao questionEsDao; @Override public void run (String... args) { List<Question> questionList = questionService.list(); if (CollUtil.isEmpty(questionList)) { return ; } List<QuestionEsDTO> questionEsDTOList = questionList.stream() .map(QuestionEsDTO::objToDto) .collect(Collectors.toList()); final int pageSize = 500 ; int total = questionEsDTOList.size(); log.info("FullSyncQuestionToEs start, total {}" , total); for (int i = 0 ; i < total; i += pageSize) { int end = Math.min(i + pageSize, total); log.info("sync from {} to {}" , i, end); questionEsDao.saveAll(questionEsDTOList.subList(i, end)); } log.info("FullSyncQuestionToEs end, total {}" , total); } }
编写一个测试方法,将题目全量同步到 Es 中
1 2 3 4 @Test public void fullSyncQuestionToEs () { fullSyncQuestionToEs.run(); }
随后在 kibana 面板中查看所有数据,发现写入成功
1 2 3 4 5 6 GET /question/_search { "query" : { "match_all" : { } } }
7、开发 ES 搜索 1)QuestionService 新增查询接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 @Override public Page<Question> searchFromEs (QuestionQueryRequest questionQueryRequest) { Long id = questionQueryRequest.getId(); Long notId = questionQueryRequest.getNotId(); String searchText = questionQueryRequest.getSearchText(); List<String> tags = questionQueryRequest.getTags(); Long questionBankId = questionQueryRequest.getQuestionBankId(); Long userId = questionQueryRequest.getUserId(); int current = questionQueryRequest.getCurrent() - 1 ; int pageSize = questionQueryRequest.getPageSize(); String sortField = questionQueryRequest.getSortField(); String sortOrder = questionQueryRequest.getSortOrder(); BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); boolQueryBuilder.filter(QueryBuilders.termQuery("isDelete" , 0 )); if (id != null ) { boolQueryBuilder.filter(QueryBuilders.termQuery("id" , id)); } if (notId != null ) { boolQueryBuilder.mustNot(QueryBuilders.termQuery("id" , notId)); } if (userId != null ) { boolQueryBuilder.filter(QueryBuilders.termQuery("userId" , userId)); } if (questionBankId != null ) { boolQueryBuilder.filter(QueryBuilders.termQuery("questionBankId" , questionBankId)); } if (CollUtil.isNotEmpty(tags)) { for (String tag : tags) { boolQueryBuilder.filter(QueryBuilders.termQuery("tags" , tag)); } } if (StringUtils.isNotBlank(searchText)) { boolQueryBuilder.should(QueryBuilders.matchQuery("title" , searchText)); boolQueryBuilder.should(QueryBuilders.matchQuery("content" , searchText)); boolQueryBuilder.should(QueryBuilders.matchQuery("answer" , searchText)); boolQueryBuilder.minimumShouldMatch(1 ); } SortBuilder<?> sortBuilder = SortBuilders.scoreSort(); if (StringUtils.isNotBlank(sortField)) { sortBuilder = SortBuilders.fieldSort(sortField); sortBuilder.order(CommonConstant.SORT_ORDER_ASC.equals(sortOrder) ? SortOrder.ASC : SortOrder.DESC); } PageRequest pageRequest = PageRequest.of(current, pageSize); NativeSearchQuery searchQuery = new NativeSearchQueryBuilder () .withQuery(boolQueryBuilder) .withPageable(pageRequest) .withSorts(sortBuilder) .build(); SearchHits<QuestionEsDTO> searchHits = elasticsearchRestTemplate.search(searchQuery, QuestionEsDTO.class); Page<Question> page = new Page <>(); page.setTotal(searchHits.getTotalHits()); List<Question> resourceList = new ArrayList <>(); if (searchHits.hasSearchHits()) { List<SearchHit<QuestionEsDTO>> searchHitList = searchHits.getSearchHits(); for (SearchHit<QuestionEsDTO> questionEsDTOSearchHit : searchHitList) { resourceList.add(QuestionEsDTO.dtoToObj(questionEsDTOSearchHit.getContent())); } } page.setRecords(resourceList); return page; }
虽然看上去复杂,但不涉及什么逻辑,根据查询需求选择合适的搜索方法,不断构造搜索条件即可。
3)在 QuestionController 编写新的搜索接口
1 2 3 4 5 6 7 8 9 @PostMapping("/search/page/vo") public BaseResponse<Page<QuestionVO>> searchQuestionVOByPage (@RequestBody QuestionQueryRequest questionQueryRequest, HttpServletRequest request) { long size = questionQueryRequest.getPageSize(); ThrowUtils.throwIf(size > 200 , ErrorCode.PARAMS_ERROR); Page<Question> questionPage = questionService.searchFromEs(questionQueryRequest); return ResultUtils.success(questionService.getQuestionVOPage(questionPage, request)); }
8、数据同步 我们需要编写一个定时方法,每 5 分钟同步 MySQL 数据至 ES
因为 MyBatis-Plus 查询的数据是逻辑未被删除的数据,因此我们要查出所有数据并同步到 ES,因此需要再 QuestionMapper 重写一个查询所有题目的方法
1)编写查询所有题目的方法
1 2 3 4 5 6 7 public interface QuestionMapper extends BaseMapper <Question> { @Select("select * from question where updateTime >= #{minUpdateTime}") List<Question> listAllQuestion (Date minUpdateTime) ; }
2)在 /job/circle 包下编写定时方法,保证每 5 分钟都会将题目数据同步到 ES
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Component @Slf4j public class IncSyncQuestionToEs { @Resource private QuestionMapper questionMapper; @Resource private QuestionEsDao questionEsDao; @Scheduled(fixedRate = 60 * 1000) public void run () { long FIVE_MINUTES = 5 * 60 * 1000L ; Date fiveMinutesAgoDate = new Date (new Date ().getTime() - FIVE_MINUTES); List<Question> questionList = questionMapper.listQuestionWithDelete(fiveMinutesAgoDate); if (CollUtil.isEmpty(questionList)) { log.info("no inc question" ); return ; } List<QuestionEsDTO> questionEsDTOList = questionList.stream() .map(QuestionEsDTO::objToDto) .collect(Collectors.toList()); final int pageSize = 500 ; int total = questionEsDTOList.size(); log.info("IncSyncQuestionToEs start, total {}" , total); for (int i = 0 ; i < total; i += pageSize) { int end = Math.min(i + pageSize, total); log.info("sync from {} to {}" , i, end); questionEsDao.saveAll(questionEsDTOList.subList(i, end)); } log.info("IncSyncQuestionToEs end, total {}" , total); } }
前端开发 运行 openAPI 重新生成前端请求代码
更改题目列表和题目表格的查询题目接口
1 2 3 4 5 6 7 8 9 10 11 12 const res = await searchQuestionVoByPageUsingPost ({ searchText, pageSize : pageSize, sortField : 'createTime' , sortOrder : 'desc' , }); const {data, code} = await searchQuestionVoByPageUsingPost ({ ...params, sortField, sortOrder, ...filter, } as API .QuestionQueryRequest );
拓展 1、根据业务自定义 ES 词典,提高分词准确度 思路:可以参考 IK 分词插件的官方文档:https://github.com/infinilabs/analysis-ik/tree/v7.17.18?tab=readme-ov-file#dictionary-configuration
2、使用 ES 查询时,关联获取题目的动态数据 思路:先查 ES,再从 DB 查询其他的数据
3、ES 接口支持降级 需求:ES 挂了、或者未搭建 ES 环境时,照样能把项目跑起来。
思路:ES 如果查询报错,改为调用数据库查询;还可以根据 ES 客户端是否正确初始化来判断是否应该使用 ES。
4、防止重复执行定时任务 可以自定义实现一个分布式锁注解,以下仅供参考:
1)创建一个自定义注解 @DistributedLock
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @Target(ElementType.METHOD) @Retention(RetentionPolicy.RUNTIME) public @interface DistributedLock { String key () ; long leaseTime () default 30000 ; long waitTime () default 10000 ; TimeUnit timeUnit () default java.util.concurrent.TimeUnit.MILLISECONDS; }
2)创建一个切面类,用来处理 @DistributedLock 注解
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Aspect @Component public class DistributedLockAspect { @Resource private RedissonClient redissonClient; @Around("@annotation(distributedLock)") public Object around (ProceedingJoinPoint joinPoint, DistributedLock distributedLock) throws Exception { String lockKey = distributedLock.key(); long waitTime = distributedLock.waitTime(); long leaseTime = distributedLock.leaseTime(); TimeUnit timeUnit = distributedLock.timeUnit(); RLock lock = redissonClient.getLock(lockKey); boolean acquired = false ; try { acquired = lock.tryLock(waitTime, leaseTime, timeUnit); if (acquired) { return joinPoint.proceed(); } else { throw new RuntimeException ("Could not acquire lock: " + lockKey); } } catch (Throwable e) { throw new Exception (e); } finally { if (acquired) { lock.unlock(); } } } }
3)在需要加锁的方法上使用 @DistributedLock 注解即可,例如:
1 2 3 4 5 6 @Override @DistributedLock(key = "testLock", leaseTime = 20000, waitTime = 5000) public void testLock () throws InterruptedException { System.out.println("print print" ); Thread.sleep(5000L ); }
面向管理的扩展功能
题目批量管理:需求分析 + 方案设计 + 前后端开发 + 功能优化
自动缓存热门题库:需求分析 + 方案设计 + 开发实现
题目批量管理 需求分析
为了提高效率,管理员需要提供批量操作的功能,例如:
【管理员】批量向题库添加题目
【管理员】批量从题库移除题目
【管理员】批量删除题目
前端设计
如果界面允许用户选择多个题目/内容的话,就要传递多个 id 给后端
批量想题库添加题目:在题目管理页面,选中多个题目后,将这些题目 id 和题库 id 传给后端,后端添加对应的题目题库关系
批量从题库移除题目:在题库管理页面,选中多个题目后,将这些题目 id 和题库 id 传给后端,后端删除对应的题目题库关系
批量删除题目,在题目管理页面,选中多条题目后,点击删除按钮,触发确认弹框,将题目 id 传给后端并执行删除
后端设计
后端通过 循环 依次调用数据库完成操作。注意,由于是批量操作,需要使用事务,有任何失败都会抛出异常并回滚。
基础后端开发 1、批量向题库添加题目
添加前需要校验题目和题库是否存在
QuestionBankQuestionService.java:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 @Override @Transactional(rollbackFor = Exception.class) public void batchAddQuestionsToBank (List<Long> questionIdList, Long questionBankId, User loginUser) { ThrowUtils.throwIf(CollUtil.isEmpty(questionIdList), ErrorCode.PARAMS_ERROR, "题目列表为空" ); ThrowUtils.throwIf(questionBankId == null || questionBankId <= 0 , ErrorCode.PARAMS_ERROR, "题库非法" ); ThrowUtils.throwIf(loginUser == null , ErrorCode.NOT_LOGIN_ERROR); List<Question> questionList = questionService.listByIds(questionIdList); List<Long> validQuestionIdList = questionList.stream() .map(Question::getId) .collect(Collectors.toList()); ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "合法的题目列表为空" ); QuestionBank questionBank = questionBankService.getById(questionBankId); ThrowUtils.throwIf(questionBank == null , ErrorCode.NOT_FOUND_ERROR, "题库不存在" ); for (Long questionId : validQuestionIdList) { QuestionBankQuestion questionBankQuestion = new QuestionBankQuestion (); questionBankQuestion.setQuestionBankId(questionBankId); questionBankQuestion.setQuestionId(questionId); questionBankQuestion.setUserId(loginUser.getId()); boolean result = this .save(questionBankQuestion); if (!result) { throw new BusinessException (ErrorCode.OPERATION_ERROR, "向题库添加题目失败" ); } } } @Data public class QuestionBankQuestionBatchAddRequest implements Serializable { private Long questionBankId; private List<Long> questionIdList; private static final long serialVersionUID = 1L ; } @PostMapping("/add/batch") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Boolean> batchAddQuestionsToBank ( @RequestBody QuestionBankQuestionBatchAddRequest questionBankQuestionBatchAddRequest, HttpServletRequest request ) { ThrowUtils.throwIf(questionBankQuestionBatchAddRequest == null , ErrorCode.PARAMS_ERROR); User loginUser = userService.getLoginUser(request); Long questionBankId = questionBankQuestionBatchAddRequest.getQuestionBankId(); List<Long> questionIdList = questionBankQuestionBatchAddRequest.getQuestionIdList(); questionBankQuestionService.batchAddQuestionsToBank(questionIdList, questionBankId, loginUser); return ResultUtils.success(true ); }
2、批量从题库移除题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 @Override @Transactional(rollbackFor = Exception.class) public void batchRemoveQuestionsFromBank (List<Long> questionIdList, Long questionBankId) { ThrowUtils.throwIf(CollUtil.isEmpty(questionIdList), ErrorCode.PARAMS_ERROR, "题目列表为空" ); ThrowUtils.throwIf(questionBankId == null || questionBankId <= 0 , ErrorCode.PARAMS_ERROR, "题库非法" ); for (Long questionId : questionIdList) { LambdaQueryWrapper<QuestionBankQuestion> lambdaQueryWrapper = Wrappers.lambdaQuery(QuestionBankQuestion.class) .eq(QuestionBankQuestion::getQuestionId, questionId) .eq(QuestionBankQuestion::getQuestionBankId, questionBankId); boolean result = this .remove(lambdaQueryWrapper); if (!result) { throw new BusinessException (ErrorCode.OPERATION_ERROR, "从题库移除题目失败" ); } } } @PostMapping("/add/batch") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Boolean> batchAddQuestionsToBank ( @RequestBody QuestionBankQuestionBatchAddRequest questionBankQuestionBatchAddRequest, HttpServletRequest request ) { ThrowUtils.throwIf(questionBankQuestionBatchAddRequest == null , ErrorCode.PARAMS_ERROR); User loginUser = userService.getLoginUser(request); Long questionBankId = questionBankQuestionBatchAddRequest.getQuestionBankId(); List<Long> questionIdList = questionBankQuestionBatchAddRequest.getQuestionIdList(); questionBankQuestionService.batchAddQuestionsToBank(questionIdList, questionBankId, loginUser); return ResultUtils.success(true ); } @Data public class QuestionBankQuestionBatchAddRequest implements Serializable { private Long questionBankId; private List<Long> questionIdList; private static final long serialVersionUID = 1L ; } server: port: 8080 servlet: context-path: /api session: cookie: domain: hejiajun.icu same-site: lax secure: false @PostMapping("/remove/batch") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Boolean> batchRemoveQuestionsFromBank ( @RequestBody QuestionBankQuestionBatchRemoveRequest questionBankQuestionBatchRemoveRequest, HttpServletRequest request ) { ThrowUtils.throwIf(questionBankQuestionBatchRemoveRequest == null , ErrorCode.PARAMS_ERROR); Long questionBankId = questionBankQuestionBatchRemoveRequest.getQuestionBankId(); List<Long> questionIdList = questionBankQuestionBatchRemoveRequest.getQuestionIdList(); questionBankQuestionService.batchRemoveQuestionsFromBank(questionIdList, questionBankId); return ResultUtils.success(true ); } @PostMapping("/remove/batch") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Boolean> batchRemoveQuestionsFromBank ( @RequestBody QuestionBankQuestionBatchRemoveRequest questionBankQuestionBatchRemoveRequest, HttpServletRequest request ) { ThrowUtils.throwIf(questionBankQuestionBatchRemoveRequest == null , ErrorCode.PARAMS_ERROR); Long questionBankId = questionBankQuestionBatchRemoveRequest.getQuestionBankId(); List<Long> questionIdList = questionBankQuestionBatchRemoveRequest.getQuestionIdList(); questionBankQuestionService.batchRemoveQuestionsFromBank(questionIdList, questionBankId); return ResultUtils.success(true ); }
3、批量删除题目
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @Override @Transactional(rollbackFor = Exception.class) public void batchDeleteQuestions (List<Long> questionIdList) { if (CollUtil.isEmpty(questionIdList)) { throw new BusinessException (ErrorCode.PARAMS_ERROR, "要删除的题目列表为空" ); } for (Long questionId : questionIdList) { boolean result = this .removeById(questionId); if (!result) { throw new BusinessException (ErrorCode.OPERATION_ERROR, "删除题目失败" ); } LambdaQueryWrapper<QuestionBankQuestion> lambdaQueryWrapper = Wrappers.lambdaQuery(QuestionBankQuestion.class) .eq(QuestionBankQuestion::getQuestionId, questionId); result = questionBankQuestionService.remove(lambdaQueryWrapper); if (!result) { throw new BusinessException (ErrorCode.OPERATION_ERROR, "删除题目题库关联失败" ); } } } @Data public class QuestionBatchDeleteRequest implements Serializable { private List<Long> questionIdList; private static final long serialVersionUID = 1L ; } @PostMapping("/delete/batch") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Boolean> batchDeleteQuestions (@RequestBody QuestionBatchDeleteRequest questionBatchDeleteRequest, HttpServletRequest request) { ThrowUtils.throwIf(questionBatchDeleteRequest == null , ErrorCode.PARAMS_ERROR); questionService.batchDeleteQuestions(questionBatchDeleteRequest.getQuestionIdList()); return ResultUtils.success(true ); } @PostMapping("/remove/batch") @AuthCheck(mustRole = UserConstant.ADMIN_ROLE) public BaseResponse<Boolean> batchRemoveQuestionsFromBank ( @RequestBody QuestionBankQuestionBatchRemoveRequest questionBankQuestionBatchRemoveRequest, HttpServletRequest request ) { ThrowUtils.throwIf(questionBankQuestionBatchRemoveRequest == null , ErrorCode.PARAMS_ERROR); Long questionBankId = questionBankQuestionBatchRemoveRequest.getQuestionBankId(); List<Long> questionIdList = questionBankQuestionBatchRemoveRequest.getQuestionIdList(); questionBankQuestionService.batchRemoveQuestionsFromBank(questionIdList, questionBankId); return ResultUtils.success(true ); }
前端开发 主要是修改题目管理页面,增加批量操作能力。
1、批量操作
Ant Design ProComponents 的 ProTable 组件自带批量操作功能,可以参考 官方文档 。
给 ProTable 组件增加如下属性,要重点注意修改 ProTable 组件的 rowKey=”id”,作为多选行的唯一标识。
为什么我选了一行,表格中所有行都会被选中,那是因为选中某行是根据 rowKey 判断的,我们只需将 rowKey 改为 id 即可
对月某些比较危险的操作,我们可以添加弹出框来防止管理执行了不当操作,此时我们可以通过 ant design 的 popconfirm 组件实现,https://ant-design.antgroup.com/components/popconfirm-cn
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 <ProTable <API .Question > rowKey="id" rowSelection={{ selections : [Table .SELECTION_ALL , Table .SELECTION_INVERT ], }} tableAlertRender={({ selectedRowKeys, selectedRows, onCleanSelected, } ) => return ( <Space size ={24} > <span > 已选 {selectedRowKeys.length} 项 <a style ={{ marginInlineStart: 8 }} onClick ={onCleanSelected} > 取消选择 </a > </span > </Space > ); }} tableAlertOptionRender={({ selectedRowKeys, selectedRows, onCleanSelected, } ) => return ( <Space size ={16} > <Button onClick ={() => { // 打开弹窗 }} > 批量向题库添加题目 </Button > <Button onClick ={() => { // 打开弹窗 }} > 批量从题库移除题目 </Button > <Popconfirm title ="确认删除" description ="你确定要删除这些题目么?" onConfirm ={() => { // 批量删除题目 }} okText="Yes" cancelText="No" > <Button danger > 批量删除题目</Button > </Popconfirm > </Space > ); }} />
此外,我们上述的代码还有一些其他的问题,比如:1608639807578177538_0.04534199560803276
稳定性低,有一道题目报错,就全部出错了
性能较低,同时操作的题目较多时,执行时间会很长
批处理操作优化 一般情况下,我们可以从以下多个角度对批处理任务进行优化。
健壮性 健壮性是指系统在面对 异常情况或不合法输入 时仍能表现出合理的行为。一个健壮的系统能够 预见和处理异常 ,并且即使发生错误,也不会崩溃或产生不可预期的行为。
1、参数校验提前
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 @Override @Transactional(rollbackFor = Exception.class) public void batchAddQuestionsToBank (List<Long> questionIdList, Long questionBankId, User loginUser) { ThrowUtils.throwIf(CollUtil.isEmpty(questionIdList), ErrorCode.PARAMS_ERROR, "题目列表为空" ); ThrowUtils.throwIf(questionBankId == null || questionBankId <= 0 , ErrorCode.PARAMS_ERROR, "题库非法" ); ThrowUtils.throwIf(loginUser == null , ErrorCode.NOT_LOGIN_ERROR); List<Question> questionList = questionService.listByIds(questionIdList); List<Long> validQuestionIdList = questionList.stream() .map(Question::getId) .collect(Collectors.toList()); ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "合法的题目列表为空" ); LambdaQueryWrapper<QuestionBankQuestion> lambdaQueryWrapper = Wrappers.lambdaQuery(QuestionBankQuestion.class) .eq(QuestionBankQuestion::getQuestionBankId, questionBankId) .in(QuestionBankQuestion::getQuestionId, validQuestionIdList); List<QuestionBankQuestion> existQuestionList = this .list(lambdaQueryWrapper); Set<Long> existQuestionIdSet = existQuestionList.stream() .map(QuestionBankQuestion::getId) .collect(Collectors.toSet()); validQuestionIdList = validQuestionIdList.stream().filter(questionId -> { return !existQuestionIdSet.contains(questionId); }).collect(Collectors.toList()); ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "所有题目都已存在于题库中" ); QuestionBank questionBank = questionBankService.getById(questionBankId); ThrowUtils.throwIf(questionBank == null , ErrorCode.NOT_FOUND_ERROR, "题库不存在" ); for (Long questionId : validQuestionIdList) { QuestionBankQuestion questionBankQuestion = new QuestionBankQuestion (); questionBankQuestion.setQuestionBankId(questionBankId); questionBankQuestion.setQuestionId(questionId); questionBankQuestion.setUserId(loginUser.getId()); boolean result = this .save(questionBankQuestion); if (!result) { throw new BusinessException (ErrorCode.OPERATION_ERROR, "向题库添加题目失败" ); } } }
2、异常处理
目前虽然已经对每一次插入操作的结果都进行了判断,并且抛出自定义异常,但是有些特殊的异常并没有被捕获。比如:
数据唯一键重复插入问题,会抛出 DataIntegrityViolationException。
数据库连接问题、事务问题等导致操作失败时抛出 DataAccessException。
其他的异常可以通过日志记录详细错误信息,便于后期追踪(全局异常处理器也有这个能力)。
稳定性 1、避免长事务问题
批量操作中,一次性处理过多数据会导致事务过长,影响数据库性能。可以通过 分批处理 来避免长事务问题,确保部分数据异常不会影响整个批次的数据保存。
假设操作 10w 条数据,其中有 1 条数据操作异常,如果是长事务,那么修改的 10w 条数据都需要回滚,而分批事务仅需回滚一批既可,降低长事务带来的资源消耗,同时也提升了稳定性。
编写一个新的方法,用于对某一批操作进行事务管理:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Override @Transactional(rollbackFor = Exception.class) public void batchAddQuestionsToBankInner (List<QuestionBankQuestion> questionBankQuestions) { for (QuestionBankQuestion questionBankQuestion : questionBankQuestions) { long questionId = questionBankQuestion.getQuestionId(); long questionBankId = questionBankQuestion.getQuestionBankId(); try { boolean result = this .save(questionBankQuestion); ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR, "向题库添加题目失败" ); } catch (DataIntegrityViolationException e) { log.error("数据库唯一键冲突或违反其他完整性约束,题目 id: {}, 题库 id: {}, 错误信息: {}" , questionId, questionBankId, e.getMessage()); throw new BusinessException (ErrorCode.OPERATION_ERROR, "题目已存在于该题库,无法重复添加" ); } catch (DataAccessException e) { log.error("数据库连接问题、事务问题等导致操作失败,题目 id: {}, 题库 id: {}, 错误信息: {}" , questionId, questionBankId, e.getMessage()); throw new BusinessException (ErrorCode.OPERATION_ERROR, "数据库操作失败" ); } catch (Exception e) { log.error("添加题目到题库时发生未知错误,题目 id: {}, 题库 id: {}, 错误信息: {}" , questionId, questionBankId, e.getMessage()); throw new BusinessException (ErrorCode.OPERATION_ERROR, "向题库添加题目失败" ); } } }
注意:在 Spring 中调用标注有 @Transactional 方法是不能直接调用的,否则事务不会生效,因为 @Transactional 是基于代理实现的,因次我们调用这个方法需要通过代理类来调用
那该如何开启代理并调用代理类?
1)首先在 Spring Boot 启动类,加上一下注解
1 @EnableAspectJAutoProxy(proxyTargetClass = true, exposeProxy = true)
2)通过以下方法获取代理对象
1 QuestionBankQuestionServiceImpl questionBankQuestionService = (QuestionBankQuestionServiceImpl) AopContext.currentProxy();
3)通过代理对象调用批量插入题库的方法
1 questionBankQuestionService.batchAddQuestionsToBankInner(questionBankQuestions);
完整代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 @Override @Transactional(rollbackFor = Exception.class) public void batchAddQuestionsToBank (List<Long> questionIdList, Long questionBankId, User loginUser) { ThrowUtils.throwIf(CollUtil.isEmpty(questionIdList), ErrorCode.PARAMS_ERROR, "题目列表为空" ); ThrowUtils.throwIf(questionBankId == null || questionBankId <= 0 , ErrorCode.PARAMS_ERROR, "题库非法" ); ThrowUtils.throwIf(loginUser == null , ErrorCode.NOT_LOGIN_ERROR); List<Question> questionList = questionService.listByIds(questionIdList); List<Long> validQuestionIdList = questionList.stream() .map(Question::getId) .collect(Collectors.toList()); ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "合法的题目列表为空" ); LambdaQueryWrapper<QuestionBankQuestion> lambdaQueryWrapper = Wrappers.lambdaQuery(QuestionBankQuestion.class) .eq(QuestionBankQuestion::getQuestionId, questionBankId) .notIn(QuestionBankQuestion::getQuestionId, validQuestionIdList); List<QuestionBankQuestion> notExistQuestionList = this .list(lambdaQueryWrapper); validQuestionIdList = notExistQuestionList.stream().map(QuestionBankQuestion::getQuestionId).collect(Collectors.toList()); ThrowUtils.throwIf(CollUtil.isEmpty(validQuestionIdList), ErrorCode.PARAMS_ERROR, "所有题目都已存在于题库中" ); QuestionBank questionBank = questionBankService.getById(questionBankId); ThrowUtils.throwIf(questionBank == null , ErrorCode.NOT_FOUND_ERROR, "题库不存在" ); int batchSize = 1000 ; int total = validQuestionIdList.size(); for (int i = 0 ; i < total; i += batchSize) { List<Long> subQuestionList = validQuestionIdList.subList(i, Math.min(i + batchSize, total)); List<QuestionBankQuestion> questionBankQuestions = subQuestionList.stream().map(questionId -> { QuestionBankQuestion questionBankQuestion = new QuestionBankQuestion (); questionBankQuestion.setQuestionBankId(questionBankId); questionBankQuestion.setQuestionId(questionId); questionBankQuestion.setUserId(loginUser.getId()); return questionBankQuestion; }).collect(Collectors.toList()); QuestionBankQuestionServiceImpl questionBankQuestionService = (QuestionBankQuestionServiceImpl) AopContext.currentProxy(); questionBankQuestionService.batchAddQuestionsToBankInner(questionBankQuestions); } }
无论接口方法是否加上 @Transactional 注解,只要实现类方法加上,事务都不会失效
在同一个对象中调用含有 @Transactional 注解的方法会导致事务失效,要通过代理对象调用
2、重试机制
由于网络不稳定等原因导致操作失败了,可以设计 重试机制 来保证系统的稳定性,适用于执行时间很长的操作
注意重试机制得有一个上限
1 2 3 4 5 6 7 8 9 10 11 12 13 int retryCount = 3 ;for (int i = 0 ; i < retryCount; i++) { try { break ; } catch (Exception e) { log.warn("插入失败,重试次数: {}" , i + 1 ); if (i == retryCount - 1 ) { throw new BusinessException (ErrorCode.OPERATION_ERROR, "多次重试后操作仍然失败" ); } } }
3、中断恢复
如果在批量插入过程中由于某种原因(如数据库宕机、服务器重启)导致批处理中断,建议设计一种机制来进行 增量恢复 。比如可以为每次操作打上批次标记,在操作未完成时记录操作状态(如部分题目成功添加),并在恢复时继续执行未完成的操作。
可以设计一个数据库表存储批次的状态:
1 2 3 4 5 6 7 create table question_batch_status ( batch_id bigint primary key, question_bank_id bigint , total_questions int , processed_questions int , status varchar (20 ) );
通过该表可以跟踪每次批处理的进度,并在失败时根据批次继续处理。
但对于我们的题目管理功能,不用那么复杂,可以直接通过判断数据是否已经满足要求来对要新处理的数据进行过滤。比如添加题目到题库前,先查一下是否已经添加到题库里了,如果已添加就不用重复添加了。(前面 参数校验提前 就已经实现了这个功能)
性能优化 1、批量操作
当前代码中,每个题目是单独插入数据库的,这会产生频繁的数据库交互。
大多数 ORM 框架和数据库驱动都支持批量插入,可以通过批量插入来优化性能,比如 MyBatis Plus 提供了 saveBatch 方法。
优化后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Override @Transactional(rollbackFor = Exception.class) public void batchAddQuestionsToBankInner (List<QuestionBankQuestion> questionBankQuestions) { try { boolean result = this .saveBatch(questionBankQuestions); ThrowUtils.throwIf(!result, ErrorCode.OPERATION_ERROR, "向题库添加题目失败" ); } catch (DataIntegrityViolationException e) { log.error("数据库唯一键冲突或违反其他完整性约束, 错误信息: {}" , e.getMessage()); throw new BusinessException (ErrorCode.OPERATION_ERROR, "题目已存在于该题库,无法重复添加" ); } catch (DataAccessException e) { log.error("数据库连接问题、事务问题等导致操作失败 错误信息: {}" , e.getMessage()); throw new BusinessException (ErrorCode.OPERATION_ERROR, "数据库操作失败" ); } catch (Exception e) { log.error("添加题目到题库时发生未知错误, 错误信息: {}" , e.getMessage()); throw new BusinessException (ErrorCode.OPERATION_ERROR, "向题库添加题目失败" ); } }
批量操作的好处:
降低数据库连接和提交的频率
避免频繁的数据库交互,减少 I/O 操作,显著提升性能
💡类似的,Redis 也提供了批处理方法,比如 Pipeline。
2、SQL 优化
我们操作数据库的时候,可以用一些 SQL 优化的技巧
最经典的优化技巧就是 select 需要的列而不是 select *,降低内存的占用
1 2 LambdaQueryWrapper<Question> questionLambdaQueryWrapper = Wrappers.lambdaQuery(Question.class).select(Question::getId).in(Question::getId, questionIdList); List<Long> validQuestionIdList = questionService.listObjs(questionLambdaQueryWrapper, obj -> (Long) obj);
3、并发编程
由于我们已经将操作分批处理,在操作较多、追求处理时间的情况下,可以通过并发编程让每批操作同时执行,而不是一批处理完再执行下一批,能够大幅提升性能。
Java 中,可以利用并发包中的 CompletableFuture + 线程池 来并发处理多个任务。
CompletableFuture 是 Java 8 中引入的一个类,用于表示异步操作的结果。它是 Future 的增强版本,不仅可以表示一个异步计算,还可以对异步计算的结果进行组合、转换和处理,实现异步任务的编排 。
比如下列代码,将任务拆分为多个子任务,并发执行,最后通过 CompletableFuture.allOf 方法阻塞等待,只有所有的子任务都完成,才会执行后续代码:
CompletableFuture 默认使用 Java 7 引入的 ForkJoinPool 线程池来并发执行任务。该线程池特别适合需要分治法来处理的大量并发任务,支持递归任务拆分。Java 8 中的并行流默认也是使用了 ForkJoinPool 进行并发处理
ForkJoinPool 的主要特性:
工作窃取算法(Work-Stealing):线程可以从其他线程的工作队列中“窃取”任务,以提高 CPU 的使用率和程序的并行性。
递归任务处理:支持将大任务拆分为多个小任务并行执行,然后再将结果合并。
💡 但是要注意,CompletableFuture 默认使用的是 ForkJoinPool.commonPool() 方法得到的线程池,这是一个全局共享的线程池,如果有多种不同的任务都依赖该线程池进行处理,可能会导致资源争抢、代码阻塞等不确定的问题。所以建议针对每种任务,自定义线程池来处理,实现线程池资源的隔离。
Java 内置了很多种不同的线程池,比如单线程的线程池、固定线程的线程池、自定义线程池等等,一般情况下我们会根据业务和资源情况 自定义线程池 。下面是一个示例:
1 2 3 4 5 6 7 8 9 ThreadPoolExecutor customExecutor = new ThreadPoolExecutor ( 4 , 10 , 60L , TimeUnit.SECONDS, new LinkedBlockingQueue <>(1000 ), new ThreadPoolExecutor .CallerRunsPolicy() );
此处画个重点,大家只要记住一个公式:
对于计算密集型任务(消耗 CPU 资源), 设置核心线程数为 n+1 或者 n(n 是 CPU 核心数),可以充分利用 CPU, 多一个线程是为了可以在某些线程短暂阻塞或执行调度时,确保有足够的线程保持 CPU 繁忙,最大化 CPU 的利用率。
对于 IO 密集型任务(消耗 IO 资源),可以增大核心线程数为 CPU 核心数的 2 - 4 倍,可以提升并发执行任务的数量。
注意,虽然并发编程能够提升性能,但也会占用更多的资源,并且给系统引入更多的不确定性。比如某个任务出现异常时,其他任务可能正在执行,产生不确定的影响。对此,可以根据情况给异步任务补充异常处理行为,通过 exceptionally 方法就能实现,示例代码如下:
1 2 3 4 5 6 CompletableFuture<Void> future = CompletableFuture.runAsync(() -> { questionBankQuestionService.batchAddQuestionsToBankInner(questionBankQuestions); }, customExecutor).exceptionally(ex -> { log.error("批处理任务执行失败" , ex); return null ; });
4、异步任务优化
将批量操作的处理变成提交一个后台任务,提交后台任务后,接口可以直接给前端返回已提交的任务 id。后台可以根据情况选择时机去执行之前提交的后台任务(比如通过定时任务或者消息队列)。
业务流程对应的示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 @PostMapping("/start") public String startTask () { String taskId = UUID.randomUUID().toString(); executeLongRunningTask(taskId); return taskId; }
前端可以通过轮询调用接口、WebSocket、SSE 等方式得知任务的执行进度。比如后端提供一个根据任务 id 查询状态的接口:
1 2 3 4 public TaskStatus queryTaskStatus (String taskId) { return taskService.getTaskStatus(taskId); }
注意,这种方案相当于改造了业务流程,成本较大,适合需要较长执行时间、或者需要对任务状态进行记录复盘的场景。
怎么实现异步任务呢?
1)立即执行异步任务
可以直接给要异步执行的方法加上 Spring 提供的 @Async 注解,或者手动使用 CompletableFuture 来异步执行任务。
1 2 3 4 5 6 @Async @Override @Transactional(rollbackFor = Exception.class) public void batchAddQuestionsToBankInner (List<QuestionBankQuestion> questionBankQuestions) { }
2)定时任务
可以将任务信息保存到数据库中,通过 Spring Scheduler 定时任务持续扫描数据库中 未执行的任务 来执行。
3)通过消息队列进行任务分发
对于长时间的批量任务,还可以考虑使用 消息队列 (如 RabbitMQ、Kafka)来异步处理任务。将任务放入消息队列,由消费者(后台服务)异步执行任务。
示例代码:
1 2 3 4 5 6 7 8 9 10 11 @PostMapping("/start") public String startTask () { String taskId = UUID.randomUUID().toString(); messageQueueService.sendMessage(new TaskMessage (taskId)); return taskId; }
后台消费者接收到消息后处理:
1 2 3 4 5 6 7 8 9 10 11 12 @RabbitListener(queues = "batch-task-queue") public void processBatchTask (TaskMessage taskMessage) { Long taskId = taskMessage.getTaskId(); Task task = getById(taskId); doSomething(task); }
5、数据库连接池调优
数据库连接池是用于管理与数据库之间连接的资源池,它能够 复用 现有的数据库连接,而不是在每次请求时都新建和销毁连接,从而提升系统的性能和响应速度。
常见的数据库连接池有 2 种:
1)HikariCP:被认为是市场上最快的数据库连接池之一,具有非常低的延迟和高效的性能。它以其轻量级和简洁的设计闻名,占用较少的内存和 CPU 资源。
Spring Boot 2.x 版本及以上默认使用 HikariCP 作为数据库连接池。
2)Druid :由阿里巴巴开发的开源数据库连接池,提供了丰富的监控和管理功能,包括 SQL 分析、性能监控和慢查询日志等。适合需要深度定制和监控的企业级应用。
在使用 Spring Boot 2.x 的情况下,默认 HikariCP 连接池大小是 10,当前请求量大起来之后,如果数据库执行的不够快,那么请求都会被阻塞等待获取连接池的连接上。
比如鱼皮自己业务中出现的情况,获取数据库连接等待时间花了 17.43s,这就是典型的数据库连接不够用。如果项目的数据库连接池较小,此时应该调大数据库连接池的大小:
如何进行数据库连接池调优呢?肯定不是凭感觉猜测,而是要通过监控或测试进行分析。
本项目使用 Druid 来做数据库连接池,因为它提供了丰富的监控和管理功能,更适合学习上手数据库连接池调优。
引入 Druid 连接池 可以参考 官方文档 引入(虽然也没什么好参考的)。
1)通过 Maven 引入 Druid,并且排除默认引入的 HikariCP:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <dependency > <groupId > com.alibaba</groupId > <artifactId > druid-spring-boot-starter</artifactId > <version > 1.2.23</version > </dependency > <dependency > <groupId > org.mybatis.spring.boot</groupId > <artifactId > mybatis-spring-boot-starter</artifactId > <version > 2.2.2</version > <exclusions > <exclusion > <groupId > com.zaxxer</groupId > <artifactId > HikariCP</artifactId > </exclusion > </exclusions > </dependency >
2)修改 application.yml 文件配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 spring: datasource: driver-class-name: com.mysql.cj.jdbc.Driver url: jdbc:mysql://localhost:3306/mianshiya username: root password: 123456 type: com.alibaba.druid.pool.DruidDataSource druid: initial-size: 10 minIdle: 10 max-active: 10 max-wait: 60000 time-between-eviction-runs-millis: 2000 min-evictable-idle-time-millis: 600000 max-evictable-idle-time-millis: 900000 validationQuery: select 1 testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true maxOpenPreparedStatements: 20 keepAlive: true aop-patterns: "com.springboot.template.dao.*" filters: stat,wall,log4j2 filter: stat: enabled: true db-type: mysql log-slow-sql: true slow-sql-millis: 2000 slf4j: enabled: true statement-log-error-enabled: true statement-create-after-log-enabled: false statement-close-after-log-enabled: false result-set-open-after-log-enabled: false result-set-close-after-log-enabled: false web-stat-filter: enabled: true url-pattern: /* exclusions: "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*" session-stat-enable: true session-stat-max-count: 1000 stat-view-servlet: enabled: true url-pattern: /druid/* reset-enable: false login-username: root login-password: 123 allow: 127.0 .0 .1 deny:
3)启动后访问监控面板:http://localhost:8101/api/druid/index.html
去除底部广告
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @Configuration @ConditionalOnWebApplication @AutoConfigureAfter(DruidDataSourceAutoConfigure.class) @ConditionalOnProperty(name = "spring.datasource.druid.stat-view-servlet.enabled", havingValue = "true", matchIfMissing = true) public class RemoveDruidAdConfig { @Bean public FilterRegistrationBean removeDruidAdFilterRegistrationBean (DruidStatProperties properties) { DruidStatProperties.StatViewServlet config = properties.getStatViewServlet(); String pattern = config.getUrlPattern() != null ? config.getUrlPattern() : "/druid/*" ; String commonJsPattern = pattern.replaceAll("\\*" , "js/common.js" ); final String filePath = "support/http/resources/js/common.js" ; Filter filter = new Filter () { @Override public void init (FilterConfig filterConfig) throws ServletException {} @Override public void doFilter (ServletRequest request, ServletResponse response, FilterChain chain) throws IOException, ServletException { chain.doFilter(request, response); response.resetBuffer(); String text = Utils.readFromResource(filePath); text = text.replaceAll("<a.*?banner\"></a><br/>" , "" ); text = text.replaceAll("powered.*?shrek.wang</a>" , "" ); response.getWriter().write(text); } @Override public void destroy () {} }; FilterRegistrationBean registrationBean = new FilterRegistrationBean (); registrationBean.setFilter(filter); registrationBean.addUrlPatterns(commonJsPattern); return registrationBean; } }
使用 Druid 监控 我们将数据库连接数改为 1,获取等待超时时间为 2s:
1 2 3 4 5 6 7 druid: initial-size: 1 minIdle: 1 max-active: 1 max-wait: 2000
然后任意执行一次对数据库的批量操作,比如插入 20 条数据,每批 2 条,一共 10 批,会随机报错:
查看 Druid 监控,可以看到最大并发为 1,因为连接池的连接数量只有 1:
除了 SQL 的监控,还有 URI 的监控,可以看到是哪个接口调用了数据库,执行了多少时间。以后出现线上数据库卡死的问题时,很快就能定位到是哪个接口、哪个 SQL 出现了问题(或者访问频率过高)。
💡 Druid 的 URI 监控是怎么实现的?
核心实现方法如下:
通过基于 Servlet 的过滤器 WebStatFilter 来拦截请求,该过滤器会收集关于请求的相关信息,比如请求的 URI、执行时长、请求期间执行的 SQL 语句数等。
统计 URI 和 SQL 执行情况是怎么关联起来的呢? 每次执行 SQL 时,Druid 会在内部统计该 SQL 的执行情况,而 WebStatFilter 会把 SQL 执行信息与当前的 HTTP 请求 URI 关联起来。
何时该调整数据库连接数呢?
有的时候,即使我们服务器 JVM 的内存和 CPU 占用都非常低,其他的中间件比如 MySQL 和 Redis 的占用也非常低,但系统依然会出现响应慢、卡死的情况。这可能就是因为一些配置错误,所以了解这些知识还是非常有必要的。
数据一致性 1、事务管理
我们目前已经使用了 @Transactional(rollbackFor = Exception.class) 来保证数据一致性。如果任意一步操作失败,整个事务会回滚,确保数据一致性。
2、并发管理
在高并发场景下,如果多个管理员同时向同一个题库添加题目,可能会导致冲突或性能问题。为了解决并发问题,确保数据一致性和稳定性,可以有 2 种常见的策略:
1)增加 分布式锁 来防止同一个接口(或方法)在同一时间被多个管理员同时操作,比如使用 Redis + Redisson 实现分布式锁。
2)如果要精细地对某个数据进行并发控制,可以选用 乐观锁 。比如通过给 QuestionBank 表增加一个 version 字段,在更新时检查版本号是否一致,确保对同一个题库的并发操作不会相互干扰。
伪代码实例:
1 2 3 4 5 6 7 8 9 QuestionBank questionBank = questionBankService.getById(questionBankId);Long currentVersion = questionBank.getVersion();int rowsAffected = questionBankService.updateVersionById(questionBankId, currentVersion);if (rowsAffected == 0 ) { throw new BusinessException (ErrorCode.CONCURRENT_MODIFICATION, "数据已被其他用户修改" ); }
💡 在 MySQL 中,还可以采用 SELECT ... FOR UPDATE 来强行锁定某一行数据,直到当前事务提交或回滚之前,防止其他事务对这行数据进行修改。
本项目中,由于关联表有唯一键约束,保证不会重复,所以不需要用这种方案。
可观测性 可观测性的关键在于以下三个方面:
可见性:系统需要能够报告它的内部状态。这个优化方案通过返回 BatchAddResult 提供了丰富的状态反馈。
追踪性:通过详细的错误原因和具体失败项,可以轻松地追踪问题源头。
诊断性:明确的反馈信息有助于快速诊断问题,而不仅仅是提供一个简单的 “成功” 或 “失败”。
2、监控
监控是实现可观测性的主流手段,你可以对服务器、JVM、请求、以及项目中引入的各种组件进行监控。
常用的监控工具有 Grafana,如果你给项目引入了某个技术组件,一般都会自带监控,比如项目调用数据库的情况可以通过 Druid 监控、Elasticsearch 可以通过 Kibana 监控等等、Spring Boot 内置了 Spring Boot Actuator 来监控应用运行状态等。
💡 如果你使用的是第三方云服务,比如 XX 云的云数据库,一般都会自带成熟的监控面板,有时间建议大家多去逛逛云服务平台,能看到很多业界成熟的监控方案。
3、返回值优化
目前我们的方法返回的是 void,这意味着在执行过程中没有明确反馈操作的结果。为了提升可观测性,我们可以根据任务的执行状态返回更加详细的结果,帮助调用者了解任务的执行情况。
可以定义一个返回结果对象,包含每个题目的处理状态、成功和失败的数量,以及失败的原因。
1 2 3 4 5 6 public class BatchAddResult { private int total; private int successCount; private int failureCount; private List<String> failureReasons; }
在批量操作中出现问题时,可以不抛出异常并中断其他的操作,只是记录部分失败的操作情况。这样一来,管理员可以知道哪些题目操作成功、哪些失败,更好地进行后续处理。
以下为示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public BatchAddResult batchAddQuestionsToBank (List<Long> questionIdList, Long questionBankId, User loginUser) { BatchAddResult result = new BatchAddResult (); result.setTotal(questionIdList.size()); for (Long questionId : questionIdList) { try { saveQuestionToBank(questionId, questionBankId, loginUser); result.setSuccessCount(result.getSuccessCount() + 1 ); } catch (Exception e) { result.setFailureCount(result.getFailureCount() + 1 ); result.getFailureReasons().add("题目ID " + questionId + " 插入失败:" + e.getMessage()); } } return result; }
OK,学到了这么多优化方法,大家可以自己根据情况选用。
自动缓存热门题库 需求分析 随着用户的日益增长,对系统的性能和稳定性的要求也越来越高
对于本系统,为了减少用户题目和加载网页的时间,可以对经常访问的数据进行缓存,而不是每次都从数据库查询
重用的缓存就是 Redis + Caffine,因此本项目可以引入缓存将热门题目缓存,减少题目的加载时间
由于有的数据被经常访问,有的不会,我们需要自动监测哪些是热点数据,并将这些热点数据缓存起来,保证系统的稳定性和用户体验
为什么需要自动发现热点? 因为热点的瞬时流量大,需要及时发现与缓存。如果靠人为来手动设置,可能刚打开后台页面,系统就已经崩溃了,一般要求秒级发现热点且自动缓存。
那么回归到本项目的需求,我们希望自动为频繁访问的题库增加缓存。
具体的规则是:对于获取题库详情的请求,如果 5 秒内访问 >= 10 次,就要使用本地缓存将题库详情缓存 10 分钟,之后都从本地缓存读取。
方案设计 自动缓存热门题库需要以下五个步骤:
1、记录访问:用户每访问一次题库,统计次数 +1
2、统计访问:统计一段时间内题库的访问次数。这是最难实现的一部分。
3、阈值判断:访问频率超过一定的阈值,变为热点数据。
4、缓存数据:缓存热点数据
5、获取数据:后续访问时,从缓存中获取数据
当然,还有很多注意事项,比如热点数据如何更新?如何恢复为正常数据等等。
让你自己实现的话,你能搞定么?
hotkey 入门 京东提供了一个轻量级通用的热 key 探测中间件 hotkey 。
根据官方仓库描述:hotkey 是京东APP后台热数据探测框架,历经多次高压压测和京东 618、双 11 大促考验。
在上线运行的这段时间内,每天探测的 key 数量数十亿计 ,精准捕获了大量爬虫、刷子用户,另准确探测大量热门商品并毫秒级推送到各个服务端内存,大幅降低了热数据对数据层的查询压力,提升了应用性能。在大促期间,hotkey 的 worker 集群秒级吞吐量达到 1500 万级别。
根据官方压测:一台 8 核 8G 的机器,每秒可以处理来自于数千台服务器发来的高达 16 万个的待测 key,8 核单机吞吐量在 16 万,16 核机器每秒可达 30 万以上探测量,所以仅采用 10 台机器,即可完成每秒近 300 万次的 key 探测任务。
这是一个真正经历过实战的高性能热点 key 探测框架,整体架构如下:
核心组件 它的主要核心组件如下:
1)Etcd 集群
Etcd 作为一个高性能的配置中心,可以以极小的资源占用,提供高效的监听订阅服务。主要用于存放规则配置,各 worker 的 ip 地址,以及探测出的热 key、手工添加的热 key 等。
Etcd 常用于配置中心和注册中心,鱼皮在 编程导航的手写 RPC 项目 中讲解过。
2)client 端 jar 包
就是在服务中添加的引用 jar,引入后,就可以便捷地去判断某 key 是否热 key。同时,该 jar 完成了 key 上报、监听 Etcd 里的 rule 变化、worker 信息变化、热 key 变化,对热 key 进行本地 Caffeine 缓存等。
3)worker 端集群
worker 端是一个独立部署的 Java 程序,启动后会连接 Etcd,并定期上报自己的 ip 信息,供 client 端获取地址并进行长连接。之后,主要就是对各个 client 发来的待测 key 进行 累加计算 ,当达到 Etcd 里设定的 rule 阈值后,将热 key 推送到各个 client。
4)dashboard 控制台
控制台是一个带可视化界面的 Java 程序,也是连接到 Etcd,之后在控制台设置各个 APP 的 key 规则,譬如 2 秒出现 20 次算热 key。然后当 worker 探测出来热 key 后,会将 key 发往 etcd,dashboard 也会监听热 key 信息,进行入库保存记录。同时,dashboard 也可以手工添加、删除热 key,供各个 client 端监听。
后端开发(hotkey 实战) hotkey 搭建可以直接参考 官方的安装教程
1、安装 etcd 直接从 github 上下载最新版本的 Etcd 即可,选择对应的操作系统版本:
下载后解压压缩包,会得到 3 个脚本:
etcd:etcd 服务本身
etcdctl:客户端,用于操作 etcd,比如读写数据
etcdutl:备份恢复工具
执行 etcd 脚本后,可以启动 etcd 服务,服务默认占用 2379 和 2380 端口,作用分别如下:
2379:提供 HTTP API 服务,和 etcdctl 交互
2380:集群中节点间通讯
2、安装 hotkey worker 从 hotkey 官方仓库 下载源码,注意,本项目使用的是 hotkey v0.0.4 版本,JDK 的版本必须小于 17!否则会报找不到类的错误!
项目导入 IDEA 后,打开 worker 模块。worker 是一个 Spring Boot 项目,启动前需要先修改 applicaiton.yml 中的配置。比如端口配置(本项目使用 8900):
disruptor 是 worker 一个统计热点 key 访问次数的算法
修改完配置,点击 WorkerApplication 即可运行
如下图,此时 worker 就已经正常启动,并且连接上 Etcd 了:
后续如果要打包部署,可以通过 Maven 打包得到 worker 的 jar 包,比如在整个 hotkey 项目根目录执行 mvn package,会依次对各模块打包。
然后可以通过命令启动 worker,可以携带参数来修改配置:
1 java -jar worker-0.0.4-SNAPSHOT.jar --etcd.server=127.0.0.1:2379
3、启动 hotkey 控制台 接着打开 dashboard 项目,执行 resource 目录下的 db.sql 文件,创建 dashboard 所需的库表。hotkey 依赖 MySQL 来存储用户账号信息、热点阈值规则等。
在执行脚本前,记得先配置好 MySQL 连接,并且在 SQL 脚本文件中创建和指定数据库:
1 2 create database hotkey_db; use hotkey_db;
执行脚本如下:
从 db.sql 可以看到内置的控制台账号密码,默认是 admin/123456
然后修改下 application.yml 配置文件,包括 dashboard 占用端口号(本教程使用 8121)、数据库配置和 etcdServer 地址等:
1 2 3 4 5 6 7 8 9 10 server: port: 8901 spring: datasource: username: ${MYSQL_USER:root} password: ${MYSQL_PASS:123456} url: jdbc:mysql://${MYSQL_HOST:localhost}:3306/hotkey_db?useUnicode=true&characterEncoding=utf-8&useSSL=true&serverTimezone=UTC&useTimezone=true&serverTimezone=GMT driver-class-name: com.mysql.cj.jdbc.Driver etcd: server: ${etcdServer:http://127.0.0.1:2379}
dashboard 也是一个 SpringBoot 项目,直接在 IDEA 内执行 DashboardApplication 启动即可。
访问 http://127.0.0.1:8901,即可看到界面:
登录成功的界面:
初次使用时需要先添加 APP。建议先在用户管理菜单中,添加一个新用户,设置昵称为 APP 名称、并填写所属 APP,如 mianshiya,密码此处就设置为 123456。之后就可以登录这个新建的用户来给应用设置规则了 (当然也可以使用 admin 账户添加),而且系统会自动创建一个 APP。
随后,在规则配置中,选择对应的 APP,新增对应的热点探测规则:
如下图就是一组规则:
duration:持续时间
interval:统计的间隔
key:对哪些 key 生效
prefix:前缀
threshold:阈值
desc:描述
对第二个案例就是,以 as__ 开头的 key,在 2s 内访问此时超过 10 次就缓存 60s
4、引入 hotkey client 有 2 种引入 hotkey client 的方式:
手动源码打包
通过 Maven 远程仓库 引入
本项目中使用方式 1
从生成的 target 中找到 with-dependencies 的 jar 包,可以修改名称为 hotkey-client-0.0.4-SNAPSHOT.jar:
接着在要引入 hotkey client 的项目中创建 lib 文件夹,放入 client 的 jar 包。注意要把该 jar 包添加到 Git 仓库中,否则其他人无法正常运行你的项目。
然后通过 Maven 引入即可:
1 2 3 4 5 6 7 <dependency > <artifactId > hotkey-client</artifactId > <groupId > com.jd.platform.hotkey</groupId > <version > 0.0.4-SNAPSHOT</version > <scope > system</scope > <systemPath > ${project.basedir}/lib/hotkey-client-0.0.4-SNAPSHOT.jar</systemPath > </dependency >
但是在本项目中引入该依赖后,项目无法运行,因为 Hutool 依赖库版本冲突了。
💡 注意,使用 system 作用域并不是最佳实践,原因是 system 作用域的依赖具有 最高优先级 。它会跳过 Maven 的依赖解析机制,直接使用你指定的本地 JAR 文件,因此它的优先级会高于其他任何来自依赖树中的传递依赖或外层依赖声明。
具体来说:
跳过依赖管理:system 作用域会跳过 Maven 的依赖管理和版本解析。你必须手动管理依赖版本和路径,Maven 无法帮你解析冲突、升级版本或使用传递依赖。
无法排除依赖:由于 system 作用域是强制性的,任何试图通过 exclusions 排除这个依赖的尝试都会失败。其他模块或依赖项中的冲突问题也无法通过正常的 dependencyManagement 或 exclusions 机制来解决。
不可传递:system 作用域的依赖不会传递给其他模块。也就是说,如果你的项目被其他项目依赖,system 作用域的依赖不会自动传递给依赖你的项目。这可能导致构建或运行时的依赖问题。
路径硬编码:system 作用域的依赖路径是硬编码的,并且指定为本地文件系统的绝对路径或相对路径。这使得项目在不同开发环境中变得难以移植,也不符合 Maven 的通用依赖管理原则。
所以一般建议将依赖包通过 Maven 安装(install)到本地仓库,或者上传包到 Maven 官方库,或者在团队内部使用 Maven 私服来管理依赖。
但这里我们不这么做,考虑到教程项目,要让开发者更容易地使用项目。所以还是直接拷贝 jar,开发者就不用自己 mvn install 来安装包了,否则还可能出现报错。
其实还有更粗暴的方法,直接爆改源码中使用的 hutool 版本,但是一般不建议这么做,毕竟你不了解别人的项目,还是该自己的方便一些。
所以我们的做法是,降低项目的 hutool 版本,改动点也不多,所以还好。
比如:
1 2 3 4 if (StrUtil.isNotBlank(tagsStr)) { questionEsDTO.setTags(JSONUtil.toList(JSONUtil.parseArray(tagsStr), String.class)); } String fileSuffix = FileNameUtil.getSuffix(multipartFile.getOriginalFilename());
引入依赖后,在代码中编写初始化 client 的配置类,会读取配置文件并执行初始化逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Configuration @ConfigurationProperties(prefix = "hotkey") @Data public class HotKeyConfig { private String etcdServer = "http://127.0.0.1:2379" ; private String appName = "app" ; private int caffeineSize = 10000 ; private long pushPeriod = 1000L ; @Bean public void initHotkey () { ClientStarter.Builder builder = new ClientStarter .Builder(); ClientStarter starter = builder.setAppName(appName) .setCaffeineSize(caffeineSize) .setPushPeriod(pushPeriod) .setEtcdServer(etcdServer) .build(); starter.startPipeline(); } }
💡 如何在 Spring Boot 启动时执行初始化代码?可以参考这道面试题:https://www.mianshiya.com/question/1800329866123747329
更改 application.yml 配置,注意应用名称必须和控制台创建的一致:
1 2 3 4 5 6 hotkey: app-name: mianshiya caffeine-size: 10000 push-period: 1000 etcd-server: http://localhost:2379
启动,能够看到 1 个客户端连接:
这样就能项目中使用了。
5、了解开发者模式 只要使用 JdHotKeyStore 这个类即可非常方便地判断 key 是否成为热点和获取热点 key 对应的本地缓存。
这个类主要有如下 4 个方法可供使用:
1 2 3 4 boolean JdHotKeyStore.isHotKey(String key)Object JdHotKeyStore.get(String key) void JdHotKeyStore.smartSet(String key, Object value)Object JdHotKeyStore.getValue(String key)
1)boolean isHotKey(String key)
该方法会返回该 key 是否是热 key,如果是返回 true,如果不是返回 false,并且会将 key 上报到探测集群进行数量计算。该方法通常用于判断只需要判断 key 是否热、不需要缓存 value 的场景,如刷子用户、接口访问频率等。
2)Object get(String key)
该方法返回该 key 本地缓存的 value 值,可用于判断是热 key 后,再去获取本地缓存的 value 值,通常用于 redis 热 key 缓存。
3)void smartSet(String key, Object value)
方法给热 key 赋值 value,如果是热 key,该方法才会赋值,非热 key,什么也不做
4)Object getValue(String key)
该方法是一个整合方法,相当于 isHotKey 和 get 两个方法的整合,该方法直接返回本地缓存的 value。 如果是热 key,则存在两种情况
是返回 value
是返回 null
返回 null 是因为尚未给它 set 真正的 value,返回非 null 说明已经调用过 set 方法了,本地缓存 value 有值了。 如果不是热 key,则返回 null,并且将 key 上报到探测集群进行数量探测。
官方推荐的最佳实践
1)判断用户是否是刷子:
1 2 3 if (JdHotKeyStore.isHotKey(“pin__” + thePin)) { }
2)判断商品 id 是否是热点:
1 2 3 4 5 6 Object skuInfo = JdHotKeyStore.getValue("skuId__" + skuId);if (skuInfo == null ) { JdHotKeyStore.smartSet("skuId__" + skuId, theSkuInfo); } else { }
个人更推荐这种写法,更加清晰:
1 2 3 4 5 6 7 8 9 if (JdHotKeyStore.isHotKey(key)) { //注意是get,不是getValue。getValue会获取并上报,get是纯粹的本地获取 Object skuInfo = JdHotKeyStore.get("skuId__" + skuId); if(skuInfo == null) { JdHotKeyStore.smartSet("skuId__" + skuId, theSkuInfo); } else { //使用缓存好的value即可 } }
6、配置 hotkey 规则 根据我们的需求,判断 bank_detail_ 开头的 key,如果 5 秒访问 10 次,就会被推送到 jvm 内存中,将这个热 key 缓存 10 分钟。
对应的规则配置如下:
1 2 3 4 5 6 7 8 9 10 [ { "duration": 600, "key": "bank_detail_", "prefix": true, "interval": 5, "threshold": 10, "desc": "热门题库缓存" } ]
在控制台新增规则:
7、项目应用 hotkey 获取题库接口 getQuestionBankVOById,先通过 isHotKey 判断当前题目是否是热点题目,如果是,则从数据库获取后放入本地缓存;之后直接从本地缓存获取即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @GetMapping("/get/vo") public BaseResponse<QuestionBankVO> getQuestionBankVOById (QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request) { ThrowUtils.throwIf(questionBankQueryRequest == null , ErrorCode.PARAMS_ERROR); Long id = questionBankQueryRequest.getId(); ThrowUtils.throwIf(id <= 0 , ErrorCode.PARAMS_ERROR); String key = "bank_detail_" + id; if (JdHotKeyStore.isHotKey(key)) { Object cachedQuestionBankVO = JdHotKeyStore.get(key); if (cachedQuestionBankVO != null ) { return ResultUtils.success((QuestionBankVO) cachedQuestionBankVO); } } JdHotKeyStore.smartSet(key, questionBankVO); return ResultUtils.success(questionBankVO); }
8、测试验证 不设置规则是不会判断热点 key 的
通过接口文档 5 秒内先访问 10 次,能够看到实时热点:
debug 程序,第 11 次请求的时候虽然会判断为 hotkey,但还是不会走缓存,本次请求会设置缓存。后续就能查询缓存了。
JdHotKeyStore.smartSet 方法只有是热 key 的情况下才会设置缓存,所以第 11 次请求虽然判断已经是热 key,但由于缓存未设置因此读的还是数据库
拓展知识 1、如何更新本地缓存 需要有一个入口让缓存失效,进行人工干预。
hotkey 提供了 JdHotKeyStore.remove() 方法,可以手动删除本地缓存并移除热点 key。
还可以利用控制台手动删除:
不过一般情况下,热点信息一般都是不太会变更的数据,过期时间设置短一点即可。
2、是否能够和 redis 分布式缓存结合? 当然可以,热 key 探测 = 热 key 发现 + 本地缓存。可以只利用热 key 的判断方法,不利用热 key 的存储方法即可。
不是热 key,就查数据库。对于热 key,写缓存时,再判断一下是否为热 key,是热 key 才设置 Redis 分布式缓存。后续的热 key 就可以从分布式缓存中获取值。(缓存存储的技术或者位置变了)
利用热 key 探测的本地缓存,将原本查数据库的逻辑改为查 Redis,Redis 查不到才查询数据库,形成多级缓存。(获取原始数据的方法改变了)
3、热 key 会自动续期么?否则可能出现缓存雪崩的问题? 可以先自己测试一下。比如针对某个热点 key 再多次发送请求查询缓存,发现在热 key 生效(缓存生效)期间,如果该 key 仍然被不断访问,并不会刷新缓存时间,直到过期。
然后看下源码,就知道为什么了。源码中的逻辑是,如果已经是热 key 则不会再 push,离过期还有 2 秒内的时候,会再次 push,这样这个 key 可能被继续设置为热 key。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static boolean isHotKey (String key) { try { if (!inRule(key)) { return false ; } else { boolean isHot = isHot(key); if (!isHot) { HotKeyPusher.push(key, (KeyType)null ); } else { ValueModel valueModel = getValueSimple(key); if (isNearExpire(valueModel)) { HotKeyPusher.push(key, (KeyType)null ); } } KeyHandlerFactory.getCounter().collect(new KeyHotModel (key, isHot)); return isHot; } } catch (Exception var3) { return false ; } } private static boolean isNearExpire (ValueModel valueModel) { if (valueModel == null ) { return true ; } else { return valueModel.getCreateTime() + (long )valueModel.getDuration() - System.currentTimeMillis() <= 2000L ; } }
也就是说,如果一个 key 持续被访问,很有可能在过期前一直被设置为热点,减少了出现雪崩问题的可能性。
扩展 1)热点题目增加自动缓存
思路:跟本教程演示的热点题库完全一致。
2)编写一个注解,自动对该方法进行热 key 探测,并将返回值作为本地缓存
思路:参考 Spring Data Redis 提供的 @Cacheable 注解,可以利用 AOP 扫描注解实现。
流量安全性优化
网站流量控制和熔断(基于 Sentinel)
动态 IP 黑白名单过滤(基于 Nacos)
网站流量控制和熔断 流量安全优化的目标可以简单概括为:确保数据在传输过程中的机密性、完整性和可用性,防止未经授权的访问、篡改、泄露和攻击,同时提升网络传输效率与性能。
而从流量控制和熔断的角度来看,流量安全优化的目标又可以概括为:防止系统过载、保障服务可用性、抵御恶意流量,并确保系统能够快速从故障中恢复。这也是本期教程中我们追求的目标。
核心概念 随着网站的发展,用户量逐渐增大,特别是互联网公司,用户量更是呈指数型增长,此时一旦出现促销活动,网站的流量会大大超越平均水平,在高并发请求下系统很可能会崩溃。
对应到我们的面试刷题平台,在金三银四或金九银十面试高峰期,网站流量会变大,还可能会有各种爬虫和恶意攻击。为了避免系统崩溃和保护服务稳定性,我们需要对网站做一定的防护措施。1608639807578177538_0.1294413323883763
常见的防护措施就是 流量控制 :限制系统进入的请求数量,防止过载。
除此之外,为了进一步隔离和保护系统,防止某些组件异常时影响系统的稳定性,还会采用 熔断机制 + 降级策略 进行兜底处理,提升系统的健壮性和可用性。
下面分别对流量控制、熔断和降级进行解释
1、流量控制 流量控制是为了 防止系统被过多的请求压垮 ,确保资源合理分配并保持服务的可用性,比如对请求数量的限制。
流量控制的 3 个主要优势:1608639807578177538_0.7754967842504696
防止过载:当瞬间涌入的请求量超出系统处理能力时,会导致资源枯竭,如 CPU 和内存耗尽。流量控制通过限制系统能处理的请求数,确保不会发生过载。
避免雪崩效应:高负载下某个服务崩溃可能引发其他依赖服务的崩溃,形成连锁反应。流量控制可以有效预防这种连锁故障,避免系统雪崩。
优化用户体验:即便部分请求被拒绝或延迟处理,流量控制也能确保大部分用户的请求能够正常响应,避免全局响应时间过长的情况。1608639807578177538_0.7763346884741562
常见的实现流量控制方法有 2 种:
限流:通过固定窗口、令牌桶或漏桶等算法限制单位时间内的请求数量。
排队:当请求量超出处理能力时,部分请求进入等待队列,防止立即超载。
1608639807578177538_0.4708111848381056
主要有以下常见的流量控制类型:
1)请求频率限制:限制单位时间内单用户、单 IP 的请求数(如每秒最多 100 次请求)。
2)带宽限制:控制访问系统时消耗的带宽量或者下载速度。
3)总流量限制:限制用户或系统整体的数据传输量。
1608639807578177538_0.20668252984600444
4)细粒度控制:根据接口、用户等特定维度进行组合限流。比如限制访问特定接口时,每个用户每分钟只能访问 60 次。
2、熔断机制 可以参考:https://sentinelguard.io/zh-cn/docs/circuit-breaking.html
熔断机制的目的是 避免当下游服务发生异常时,整个系统继续耗费资源重复发起失败请求 ,从而防止连锁故障。
这类似于电路中的断路器,当检测到异常情况时,熔断器会自动切断对故障服务的调用,防止问题扩大。1608639807578177538_0.30931350357585163
工作机制:
监控服务健康状态:系统会实时监控服务的调用情况,例如请求成功率、响应时间等,判断服务的健康状况。
进入熔断状态:当某个服务的错误率达到设定阈值(如响应时间过长或出错率过高)时,系统会 激活熔断器 ,暂时停止对该服务的调用,避免消耗不必要的资源和让错误进一步扩散。
快速失败:在熔断状态下,系统不会再等待超时,而是直接返回失败响应,减少系统资源占用,并避免因长时间等待导致用户体验的恶化。(也可以降级处理)1608639807578177538_0.013142651290177776
熔断恢复机制:熔断并非永久状态。在一段时间后,熔断器会进入 半开状态 ,允许少量请求测试服务的健康情况。如果恢复正常,熔断器将关闭,恢复正常服务调用;如果仍有问题,则继续保持熔断。
熔断流程:
1608639807578177538_0.4432245777087911
举个例子,一个支付服务由于高负载频繁超时,此时熔断器会检测到支付服务的健康状况恶化,暂时切断对它的调用,防止前端系统继续发出请求。如果不采取熔断措施,支付服务的异常可能会拖垮整个系统,甚至影响其他依赖的服务模块或系统资源(比如请求连接)。
3、降级机制 降级的目的是在某个服务的响应能力下降、或该服务不可用时,提供简化版的功能或返回默认值作为 兜底 ,保持系统的部分功能可用,确保用户体验的连续性,避免系统频繁报错。
降级可以是手动配置,也可以根据系统负载自动触发。系统可能由于多种原因(如高负载、外部依赖不可用等)触发降级,返回简化的响应或默认值。
降级机制的好处:1608639807578177538_0.2694092122438603
优雅地处理故障:在降级状态下,系统不会直接返回错误信息,而是提供一个替代方案。例如,某个数据查询服务不可用时,系统可以返回缓存数据,确保用户看到的是有效信息,而非错误页面。
降低服务压力:降级有助于减轻系统对非核心服务的依赖,确保核心功能的稳定运行。例如,当推荐系统或广告服务出现故障时,降级可以减少对这些服务的调用,保护系统的整体稳定性。
举个例子,在一个电商网站上,如果商品推荐系统由于外部服务故障无法正常运行,可以触发降级机制,显示一组静态的推荐商品列表。这确保用户仍然能够顺利浏览商品页面,而不是直接看到错误信息。
是不是有点 try…catch… 的感觉?但降级这个概念显然比异常处理要更“高大上”一些,不一定是出了异常才降级,响应较慢或者受到其他服务影响可能也会触发降级。
4、熔断和降级的区别 初学者很容易把这两个概念搞混,二者是完全不同的概念,只不过经常结合使用罢了。
熔断不一定要降级,只是切断调用;降级也不一定需要熔断,单次调用失败也可以降级(比如数据库查询失败返回内存的数据)。1608639807578177538_0.8400012094483926
具体来说:
熔断是当服务健康状况恶化时,通过 切断调用 避免系统资源浪费或服务间故障扩散。
降级是在系统压力过大或某个服务不可用时,通过 提供简化的替代方案 ,保持系统的可用性和用户体验。
两者经常结合使用,先触发熔断后再进行降级。
扩展知识 - 有损服务 有损服务指的是在系统资源有限或负载较高的情况下,系统 有意识地 舍弃部分非核心服务或数据,来保证系统整体的稳定性和核心功能的可用性。简单来说,就是“丢车保帅”。
举些例子:1608639807578177538_0.6523680530059925
视频流媒体:在网络带宽不足时,流媒体平台会动态降低视频质量(如从高清降到标清),以避免中断视频播放。这就是典型的“有损”策略,牺牲画质来保证视频的流畅播放。
实时数据采集:在高并发环境下,系统可以通过丢弃部分非重要的日志或监控数据,减少数据处理压力,优先保证核心业务流程。
什么时候使用有损服务和降级?
有损服务:适用于需要在性能和质量之间做出平衡的场景,特别是 当系统资源不足 时,选择牺牲某些服务的质量来保证整体稳定。
降级:适用于需要保证系统核心功能在高负载或部分服务不可用的情况下仍能继续提供的场景。降级更多是 在功能层面进行简化 ,而非直接丢弃数据或服务。
1608639807578177538_0.34153155897027343
可以这么理解:有损服务更倾向于 整体视角 上资源的取舍,降级更倾向于保证 某个功能 的可用。
需求分析(限流熔断规则) 本项目的具体需求:要对什么资源进行限流熔断?规则是怎么样的?
我们来完成两个有代表性的需求:
对单个接口整体限流
对单个 IP 访问单个接口限流
1、查看题库列表接口限流熔断 资源:listQuestionBankVOByPage 接口
目的:控制对耗时较长的、经常访问的接口的请求频率,防止过多请求导致系统过载。
限流规则:1608639807578177538_0.5895519431203375
策略:整个接口每秒钟不超过 10 次请求
阻塞操作:提示“系统压力过大,请耐心等待”
熔断规则:
熔断条件:如果接口异常率超过 10%,或者慢调用(响应时长 > 3 秒)的比例大于 20%,触发 60 秒熔断。
熔断操作:直接返回本地数据(缓存或空数据)
2、单 IP 查看题目列表限流熔断 资源:listQuestionVoByPage 接口
限流规则:1608639807578177538_0.5206259383646323
策略:每个 IP 地址每分钟允许查看题目列表的次数不能超过 60 次。
阻塞操作:提示“访问过于频繁,请稍后再试”
熔断规则:
熔断条件:如果接口异常率超过 10%,或者慢调用(响应时长 > 3 秒)的比例大于 20%,触发 60 秒熔断。
熔断操作:直接返回本地数据(缓存或空数据)
1608639807578177538_0.9334369382223324
扩展知识 - 更多规则 以下规则感兴趣的同学可自主实现:
1)题目搜索
限流规则:每个 IP 地址每分钟允许进行的题目搜索次数,例如 100 次。
熔断操作:直接返回本地数据(缓存或空数据)
2)用户注册
限流规则:每个 IP 地址每分钟允许注册的次数,例如 5 次。超过阈值则返回用户注册频繁的错误提示,防止恶意注册。
熔断规则:如果用户注册服务出现异常率高于 5%(例如连续 5 分钟内的失败请求占总请求的比例),则触发熔断,给用户一个友好的错误提示。
3)用户登录1608639807578177538_0.07382706348810664
限流规则:每个 IP 地址每分钟允许尝试登录的次数,例如 10 次。对于频繁的失败登录尝试,可以限制登录尝试次数,防止暴力破解攻击。
熔断规则:如果登录服务的失败率超过 10% 或登录尝试次数过多(例如每分钟超过 1000 次),则触发熔断,给用户一个友好的错误提示。
实现方案(技术选型) 除了网关层(Nginx 等)实现的限流,在 Java 项目中常用来实现限流熔断相关的技术主要有以下几种:
1、Sentinel Sentinel 是阿里巴巴开源的限流、熔断、降级组件,旨在为分布式系统提供可靠的保护机制。它设计用于解决高并发流量下的稳定性问题,并且支持与 Dubbo、Spring Cloud 等多种框架集成。1608639807578177538_0.5598448193889138
它的功能:
限流:支持基于 QPS、并发数量等条件的限流,支持滑动窗口、预热、漏桶等算法。
熔断降级:支持失败率、慢调用比例等指标触发熔断,并提供自动恢复机制。
热点参数限流:可以基于特定的参数进行限流,如限制特定用户 ID 的请求频率。1608639807578177538_0.22365088046550397
系统负载保护:可以根据系统的实际负载(如 CPU、内存)动态调整流量。
丰富的规则配置:通过配置中心或控制台动态调整限流和熔断规则。
优势:功能丰富、提供控制台、更新较频繁、社区活跃、文档清晰,能够快速入门上手。
2、Hystrix Hystrix 是 Netflix 开源的一个限流、熔断和降级库。它通过熔断器模式在检测到下游服务失败率过高时中断请求,以防止系统资源耗尽。
它的功能:
熔断:当调用失败或响应超时时,触发熔断,停止调用失败的服务。
降级:在触发熔断后,调用备用逻辑或默认返回值。
隔离:Hystrix 使用线程池或信号量来隔离服务调用,防止单个服务的资源消耗影响全局。
熔断恢复:当下游服务恢复时,逐步恢复调用。
还提供了丰富的监控和告警功能,可以通过 Hystrix Dashboard 进行实时监控。
但是 它目前已经进入维护状态,不再进行新的功能更新 ,所以新项目就没必要使用了:1608639807578177538_0.34314973197738485
3、Resilience4j Resilience4j 是一个轻量级的熔断、限流、隔离、重试库,它设计灵感来源于 Netflix 的 Hystrix 框架,专门设计为响应式编程和 Java 8+ 风格下的熔断库。
优点:它很轻量级,没有外部依赖,特别适合响应式编程风格。
缺点:相比 Sentinel,功能相对较少,尤其在限流功能上不够丰富。
4、Guava RateLimiter RateLimiter 是 Guava 提供的一个限流工具,基于令牌桶算法实现,主要用于对系统的流量进行控制。
缺点:它仅支持限流,且功能相对单一,不能处理熔断等复杂场景。适合不需要复杂熔断或隔离功能的小型项目,主要用于 单机系统 的流量控制。
1 2 3 4 5 6 7 8 RateLimiter rateLimiter = RateLimiter.create(2.0 );for (int i = 0 ; i < 10 ; i++) { rateLimiter.acquire(); System.out.println("请求 " + i + " 在 " + System.currentTimeMillis() + " 执行" ); }
5、Redisson RRateLimiter Redisson 是一个基于 Redis 的 Java 驱动程序,它提供了丰富的分布式工具和数据结构,其中包括分布式锁、计数器、队列、信号量,以及限流(Rate Limiter)等功能。1608639807578177538_0.2775543579144386
Redisson 提供了 RRateLimiter 接口来支持限流操作。你可以定义时间窗口内允许的最大请求数,超出限制的请求将被阻塞或拒绝。它的限流基于 Redis 的计数器来控制访问频率,确保即使在多台服务器之间,也能有效地限制请求速率。
示例代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 RedissonClient redisson = Redisson.create(config);RRateLimiter rateLimiter = redisson.getRateLimiter("myRateLimiter" );rateLimiter.trySetRate(RRateLimiter.RateType.OVERALL, 3 , 1 , RRateLimiter.IntervalUnit.SECONDS); for (int i = 0 ; i < 10 ; i++) { boolean acquired = rateLimiter.tryAcquire(1 ); System.out.println("Request " + (i + 1 ) + " is allowed: " + acquired); }
💡编程导航的智能 BI 项目 中,就是通过 Redisson RRateLimiter 实现了限流,感兴趣的同学可以学习。
选型策略 1)从功能全面、生态成熟角度:如果需要全面的熔断、限流、降级、监控功能,同时兼容 Spring Cloud、Spring Boot、Dubbo 等微服务架构,Sentinel 是最佳选择,在我们国内公司中有较广泛应用。
2)从轻量级、响应式编程角度:如果项目采用响应式编程模型,或希望使用轻量级的熔断限流组件,Resilience4j 是非常好的选择。
3)已有 Hystrix 集成的系统:如果现有系统已经集成了 Hystrix,可以继续使用,但需要考虑未来的技术更新,推荐逐渐过渡到 Sentinel。
4)单机限流需求:对于不需要复杂熔断功能的小型应用,Guava RateLimiter 可以快速实现简单的限流。1608639807578177538_0.35619406910300677
5)分布式限流需求:对于不需要复杂熔断功能的分布式应用,Redisson 的 RRateLimiter 可以快速实现简单的限流。
本项目中,我们选择使用 Sentinel ,带大家学习一个功能强大,支持多种限流、熔断策略,支持多种框架集成的网站流量控制和熔断组件。
Sentinel 官方给出的组件对比:
Sentinel 入门 https://sentinelguard.io/zh-cn/index.html1608639807578177538_0.7696198441551441
1、核心概念 1)资源:表示要保护的业务逻辑或代码块。我们说的资源,可以是任何东西,服务、服务里的方法、甚至是一段代码。
使用 Sentinel 来进行资源保护,主要分为几个步骤:
定义资源
定义规则
检验规则是否生效1608639807578177538_0.6919617170598169
先把可能需要保护的资源定义好,之后再配置规则。 也可以理解为,只要有了资源,我们就可以在任何时候灵活地定义各种流量控制规则。在编码的时候,只需要考虑这个代码是否需要保护,如果需要保护,就将之定义为一个资源。
有多种定义资源的方法,比如编程式和注解式,参考官方文档 。
2)规则:Sentinel 使用规则来定义对资源的保护策略。
可以 参考官方文档 来了解规则,比如:
限流规则:用于控制流量的规则,设置 QPS(每秒查询量)等参数,防止系统过载。
熔断规则:用于实现熔断降级的规则,当某个资源的异常比例或响应时间超过阈值时,触发熔断,短时间内不再访问该资源。
系统规则:根据系统的整体负载(如 CPU 使用率、内存使用率等)进行保护,适合在系统级别进行流量控制。
热点参数规则:用于限制某个方法的某些热点参数的访问频率,避免某些参数导致流量过大。
授权规则:用于定义黑白名单的授权规则,控制资源访问的权限。
3)控制台: Sentinel 控制台是一个可视化的管理工具,主要用于监控、管理和配置 Sentinel 的流控规则、熔断规则等。它提供了一个友好的界面,让用户可以轻松地操作。这是 Sentinel 的核心优势,可以提升可观测性,没有 Sentinel 控制台,感觉就失去了使用它的灵魂。
4)客户端:是指集成了 Sentinel 的应用程序,通常是通过引入 Sentinel 的依赖来接入。客户端负责在本地对资源进行监控、限流、熔断,并将 数据上报 给控制台。
2、架构设计 参考官方文档的基本原理 ,总体架构设计如下:
Sentinel 将 ProcessorSlot 作为 SPI 接口进行扩展,使得 Slot Chain 具备了扩展的能力。您可以自行加入自定义的 slot 并编排 slot 间的顺序,从而可以给 Sentinel 添加自定义的功能。1608639807578177538_0.13882980675285173
对于限流系统,指标的统计依然是实现关键,Sentinel 中使用高性能的环形计数器(滑动窗口)来实现:
3、Sentinel 入门 Demo 1)引入依赖:
1 2 3 4 5 <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-core</artifactId> <version>1.8.8</version> </dependency>
2)编写 Sentinel 测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 /** * 限流测试 */ public class SentinelTest { public static void main(String[] args) { // 配置规则 initFlowRules(); while (true) { // 1.5.0 版本开始可以直接利用 try-with-resources 特性 try (Entry entry = SphU.entry("HelloWorld")) { // 被保护的逻辑 System.out.println("hello world"); } catch (BlockException ex) { // 处理被流控的逻辑 System.out.println("blocked!"); } } } /** * 定义限流规则,限制 QPS 为 20 */ private static void initFlowRules(){ List<FlowRule> rules = new ArrayList<>(); FlowRule rule = new FlowRule(); rule.setResource("HelloWorld"); rule.setGrade(RuleConstant.FLOW_GRADE_QPS); // Set limit QPS to 20. rule.setCount(20); rules.add(rule); FlowRuleManager.loadRules(rules); } }
3)运行效果:
Demo 运行之后,我们可以在日志 ~/logs/csp/${appName}-metrics.log.xxx 里看到下面的输出:
1 2 3 4 5 6 7 |--timestamp-|------date time----|--resource-|p |block|s |e|rt 1529998904000|2018-06-26 15:41:44|hello world|20|0 |20|0|0 1529998905000|2018-06-26 15:41:45|hello world|20|5579 |20|0|728 1529998906000|2018-06-26 15:41:46|hello world|20|15698|20|0|0 1529998907000|2018-06-26 15:41:47|hello world|20|19262|20|0|0 1529998908000|2018-06-26 15:41:48|hello world|20|19502|20|0|0 1529998909000|2018-06-26 15:41:49|hello world|20|18386|20|0|0
其中 p 代表通过的请求, block 代表被阻止的请求, s 代表成功执行完成的请求个数, e 代表用户自定义的异常, rt 代表平均响应时长。
可以根据使用的框架引入适配依赖,参考官方文档 。
此处直接运行 Main 方法来演示效果,JVM 参数为:-Dcsp.sentinel.dashboard.server=localhost:8131
可以 参考官网编写入门 Demo ,在本地通过 Main 方法运行一个 Sentinel 客户端程序。
运行成功后,可以在当前用户根目录下(~/logs/csp/${appName}-metrics.log.xxx)看到输出:
4、下载并启动 Sentinel 控制台 可以 参考官方文档 进行安装。
1)下载控制台 jar 包并在本地启动,可以访问从 github 上下载 release的 jar 包。
我为大家提供了软件包:https://pan.baidu.com/s/1u73-Nlolrs8Rzb1_b6X6HA ,提取码:c2sd
2)直接在命令行窗口启动 Sentinel 控制台:
注意:启动 Sentinel 控制台需要 JDK 版本为 1.8 及以上版本。
命令:
1 java -Dserver.port=8131 -jar sentinel-dashboard-1.8.8.jar
启动成功:
本地访问 http://localhost:8131/(你填的端口),即可访问控制台,**默认账号和密码都是 sentinel**
4)客户端接入控制台
引入 Maven 依赖,用于和 Sentinel 控制台通讯:
1 2 3 4 5 <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-transport-simple-http</artifactId> <version>1.8.8</version> </dependency>
程序启动时需要加入 JVM 参数 -Dcsp.sentinel.dashboard.server=consoleIp:port 指定控制台地址和端口。若启动多个应用,则需要通过 -Dcsp.sentinel.api.port=xxxx 指定客户端监控 API 的端口(默认是 8719)。
Sentinel 非常贴心,提供了很多框架整合的依赖,便于开发,比如 Spring Web 项目支持将所有的接口自动识别为资源:
还有更多的配置,比如更改日志目录等,可以看 官方文档 了解。
确保客户端有访问量 ,Sentinel 会在 客户端首次调用的时候 进行初始化,开始向控制台发送心跳包。通过控制台可以查看到实时访问情况:
查看机器列表和健康情况:
簇点链路(单机调用链路)页面实时的去拉取指定客户端资源的运行情况。它一共提供两种展示模式:一种用树状结构展示资源的调用链路,另外一种则不区分调用链路展示资源的运行情况。如图:
5、规则管理和推送 问题:Sentinel 的规则存储在哪里呢?又是如何通过控制台修改规则之后,将规则同步给客户端进行限流熔断的呢?
官方文档 有详细地介绍:Sentinel 控制台同时提供简单的规则管理以及推送的功能。规则推送分为 3 种模式,包括 “原始模式”、”Pull 模式” 和 “Push 模式”。
目前控制台的规则推送也是通过 规则查询更改 HTTP API 来更改规则。这也意味着这些规则仅在内存态生效,应用重启之后,该规则会丢失。
以上是原始模式。当了解了原始模式之后,官方建议通过 动态规则 并结合各种外部存储来定制自己的规则源。我们推荐通过动态配置源的控制台来进行规则写入和推送,而不是通过 Sentinel 客户端直接写入到动态配置源中。
在生产环境中,官方推荐 push 模式,支持自定义存储规则的配置中心,控制台改变规则后,会 push 到配置中心。
更多规则管理和推送规则可以阅读:在生产环境使用 Sentinel 。
6、整合 Spring Boot 基于 Spring Boot Starter + 注解模式开发 + 原始规则推送模式开发1608639807578177538_0.11239088707580192
Spring Boot 项目可以轻松和 Sentinel 集成,直接引入一个 starter,使用 Spring Cloud Alibaba Sentinel 即可。
在引入整合依赖时,一定要注意版本号!
建议 参考官方文档选择版本 。由于 Spring Boot 3.0,Spring Boot 2.7~2.4 和 2.4 以下版本之间变化较大,目前企业级客户老项目相关 Spring Boot 版本仍停留在 Spring Boot 2.4 以下,为了同时满足存量用户和新用户不同需求,社区以 Spring Boot 3.0 和 2.4 分别为分界线,同时维护 2022.x、2021.x、2.2.x 三个分支迭代。
本项目 Spring Boot 用的是 2.7,因此使用 Sentinel Starter 的版本 2021.0.5.0。在项目中引入依赖:
1 2 3 4 5 6 <!-- https://mvnrepository.com/artifact/com.alibaba.cloud/spring-cloud-starter-alibaba-sentinel --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId> <version>2021.0.5.0</version> </dependency>
可以看到,该依赖自动整合了 Sentinel 的 core 包、客户端通讯包、注解开发包、webmvc 适配包、热点参数限流包等:
整合包支持自动将所有的接口根据 url 路径识别为资源。启动项目后,通过接口文档测试就能看到监控效果:
注意:无论是整合 Spring Boot 的 Sentinle 还是简单的 Demo 都要加上 vm 选项:-Dcsp.sentinel.dashboard.server=localhost:8131,这样才能保证数据上报到 Sentinel 控制台
7、开发模式 Sentinel 的开发主要包括定义资源和定义规则。
1)定义资源 :支持通过代码、引入框架适配、注解方式 定义资源。
通过代码定义资源,更灵活:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Entry entry = null; // 务必保证finally会被执行 try { // 资源名可使用任意有业务语义的字符串 entry = SphU.entry("自定义资源名"); // 被保护的业务逻辑 // do something... } catch (BlockException e1) { // 资源访问阻止,被限流或被降级 // 进行相应的处理操作 } finally { if (entry != null) { entry.exit(); } }
通过注解定义资源,更快捷可读:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class TestService { // 对应的 `handleException` 函数需要位于 `ExceptionUtil` 类中,并且必须为 static 函数. @SentinelResource(value = "test", blockHandler = "handleException", blockHandlerClass = {ExceptionUtil.class}) public void test() { System.out.println("Test"); } // 原函数 @SentinelResource(value = "hello", blockHandler = "exceptionHandler", fallback = "helloFallback") public String hello(long s) { return String.format("Hello at %d", s); } // Fallback 函数,函数签名与原函数一致或加一个 Throwable 类型的参数. public String helloFallback(long s) { return String.format("Halooooo %d", s); } // Block 异常处理函数,参数最后多一个 BlockException,其余与原函数一致. public String exceptionHandler(long s, BlockException ex) { // Do some log here. ex.printStackTrace(); return "Oops, error occurred at " + s; } }
@SentinelResource 注解的配置优先于自动识别的配置。这意味着,如果注解中定义了特定的限流或熔断策略,这些策略将覆盖默认的或自动识别的配置。
推荐开发模式:优先使用适配包来自动识别资源,然后能运用注解尽量运用注解,最后再选择主动编码定义资源。
2)定义规则: 支持通过代码、控制台(推荐)、配置文件来定义规则。
比如通过代码定义一个限流规则,更灵活:
1 2 3 4 5 6 7 8 9 10 11 private static void initFlowQpsRule() { List<FlowRule> rules = new ArrayList<>(); FlowRule rule1 = new FlowRule(); rule1.setResource(resource); // Set max qps to 20 rule1.setCount(20); rule1.setGrade(RuleConstant.FLOW_GRADE_QPS); rule1.setLimitApp("default"); rules.add(rule1); FlowRuleManager.loadRules(rules); }
通过控制台配置,更高效:
一般推荐使用控制台来配置规则,但如果希望开发者更快启动和学习项目,可以通过编码定义规则,这样不用搭建控制台、而且每次启动项目都会确保规则被创建。
8、其他特性 除了限流外,Sentinel 还提供了多种规则,都可以通过官方文档来了解。
熔断降级 :用于实现熔断降级的规则,当某个资源的异常比例或响应时间超过阈值时,触发熔断,短时间内不再访问该资源。系统自适应保护 :根据系统的整体负载(如 CPU 使用率、内存使用率等)进行保护,适合在系统级别进行流量控制。热点参数限流 :用于限制某个方法的某些热点参数的访问频率,避免某些参数导致流量过大。来源访问控制 :用于定义黑白名单的授权规则,控制资源访问的权限。
接下来,我们通过本项目的需求实现,带大家实战 Sentinel 开发。
后端开发(Sentinel 实战) 1、查看题库列表接口限流熔断 资源:listQuestionBankVOByPage 接口
目的:控制对耗时较长的、经常访问的接口的请求频率,防止过多请求导致系统过载。
限流规则:
策略:整个接口每秒钟不超过 10 次请求
阻塞操作:提示“系统压力过大,请耐心等待”
熔断规则:
熔断条件:如果接口异常率超过 10%,或者慢调用(响应时长 > 3 秒)的比例大于 20%,触发 60 秒熔断。
熔断操作:直接返回本地数据(缓存或空数据)
开发模式:用注解定义资源 + 基于控制台定义规则
1)定义资源。给需要限流的接口添加 @SentinelResource 注解:
1 2 3 4 5 6 7 8 @PostMapping("/list/page/vo") @SentinelResource(value = "listQuestionBankVOByPage", blockHandler = "handleBlockException", fallback = "handleFallback") public BaseResponse<Page<QuestionBankVO>> listQuestionBankVOByPage( @RequestBody QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request) { }
定义阻塞异常要多加一个BlockException 参数,其余参数与原接口一致,定义降级操作要多一个 Throwable 参数,其余也和原接口一样,注意两个方法名称要与注解定义的名称一致
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 /** * listQuestionBankVoByPage 流程操作 * 限流:提示“系统压力过大,请耐心等待” */ public BaseResponse<Page<QuestionBankVO>> handleBlockException(@RequestBody QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request, BlockException ex) { return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统压力过大,请耐心等待"); } /** * listQuestionBankVoByPage 降级操作:直接返回本地数据 */ public BaseResponse<Page<QuestionBankVO>> handleFallback(@RequestBody QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request, Throwable ex) { return ResultUtils.success(null); }
BlockException 处理时所有限流和所有熔断之后的降级异常,而 Fallback 处理的是所有的业务异常
启动项目成功并且访问接口后,可以在控制台看到刚定义的资源:
2)实现限流阻塞和熔断降级方法。注意遵循 官方文档的方法定义规则 :
为了实现方便,尽快验证效果,我们先在接口相同的 Controller 中编写限流阻塞和降级方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * listQuestionBankVOByPage 降级操作:直接返回本地数据 */ public BaseResponse<Page<QuestionBankVO>> handleFallback(@RequestBody QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request, Throwable ex) { // 可以返回本地数据或空数据 return ResultUtils.success(null); } /** * listQuestionBankVOByPage 流控操作 * 限流:提示“系统压力过大,请耐心等待” */ public BaseResponse<Page<QuestionBankVO>> handleBlockException(@RequestBody QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request, BlockException ex) { // 限流操作 return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统压力过大,请耐心等待"); }
3)通过控制台定义规则
限流规则:根据需求配置即可
熔断规则:新增两条熔断规则,注意设置最小请求数、统计时长
4)测试
为便于测试,可以先将限流熔断规则调整到容易触发的值,然后通过接口文档测试调用,查看效果。
连续快速发送多次请求,触发限流,执行了 blockHandler 处理器的逻辑:
注意,只有业务异常(比如请求参数错误、或者数据库操作失败等问题),才会算到熔断条件中,限流熔断本身的异常 BlockException 是不计算的。
测试熔断的时候,可以故意给 sortField 请求参数传一个不存在的字段,触发业务异常。可以尝试下熔断的触发和恢复:
先通过传错业务参数触发异常,导致熔断
等待熔断结束后,再触发一次异常,还会继续熔断
过一段时间,再触发一次正常请求,则熔断解除
测试发现,任何业务异常(不仅仅是被熔断了),都会触发 fallbackHandler,该方法可作为一个通用的降级逻辑处理器。
测试发现,如果 blockHandler 和 fallbackHandler 同时配置,当熔断器打开后,仍然会进入 blockHandler 进行处理,因此需要在该方法中处理因为熔断触发的降级逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 /** * listQuestionBankVOByPage 流控操作 * 限流:提示“系统压力过大,请耐心等待” * 熔断:执行降级操作 */ public BaseResponse<Page<QuestionBankVO>> handleBlockException(@RequestBody QuestionBankQueryRequest questionBankQueryRequest, HttpServletRequest request, BlockException ex) { // 降级操作 if (ex instanceof DegradeException) { return handleFallback(questionBankQueryRequest, request, ex); } // 限流操作 return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统压力过大,请耐心等待"); }
Sentinel 的 blockHandler 处理的是BlockException,该异常表示系统受到流量控制限制(如限流或熔断),这些不是业务逻辑中的异常,因此 fallback 不会处理这些异常。如果不配置 blockHandler,才会在熔断时,进入到 fallbackHandler 中进行兜底。
总结一下:
blockHandler 处理 Sentinel 流量控制异常,如 BlockException。fallback 处理业务逻辑中的异常,比如我们自己的 BusinessException。
可以根据自己的实际情况配置。
2、单 IP 查看题目列表限流熔断 资源:listQuestionVoByPage 接口
限流规则:
策略:每个 IP 地址每分钟允许查看题目列表的次数不能超过 60 次。
阻塞操作:提示“访问过于频繁,请稍后再试”
熔断规则:
熔断条件:如果接口异常率超过 10%,或者慢调用(响应时长 > 3 秒)的比例大于 20%,触发 60 秒熔断。
熔断操作:直接返回本地数据(缓存或空数据)
由于需要针对每个用户进一步精细化限流,而不是整体接口限流,可以采用 热点参数限流机制 ,允许根据参数控制限流触发条件。
对于我们的需求,可以将 IP 地址作为热点参数。
1)定义资源
对于 @SentinelResource 注解方式定义的资源,若注解作用的方法上有参数,Sentinel 会将它们作为参数传入 SphU.entry(res, args)。比如以下的方法里面 uid 和 type 会分别作为第一个和第二个参数传入 Sentinel API,从而可以用于热点规则判断:
1 2 3 4 @SentinelResource("myMethod") public Result doSomething(String uid, int type) { // some logic here... }
由于 Controller 接口参数较杂乱,使用编程式定义资源的方法。
💡 这里建议新写一个接口,不要污染原有接口,等测试稳定后,再进行切换。
代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 // 基于 IP 限流 String remoteAddr = request.getRemoteAddr(); Entry entry = null; try { entry = SphU.entry("listQuestionVOByPage", EntryType.IN, 1, remoteAddr); // 被保护的业务逻辑 // 查询数据库 Page<Question> questionPage = questionService.listQuestionByPage(questionQueryRequest); // 获取封装类 return ResultUtils.success(questionService.getQuestionVOPage(questionPage, request)); } catch (BlockException ex) { // 资源访问阻止,被限流或被降级 if (ex instanceof DegradeException) { return handleFallback(questionQueryRequest, request, ex); } // 限流操作 return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "访问过于频繁,请稍后再试"); } finally { if (entry != null) { entry.exit(1, remoteAddr); } }
💡需要特别注意!
若 entry 的时候传入了热点参数,那么 exit 的时候也一定要带上对应的参数(exit(count, args)),否则可能会有统计错误。这个时候不能使用 try-with-resources 的方式。
SphU.entry(xxx) 需要与 entry.exit() 方法成对出现,匹配调用,否则会导致调用链记录异常,抛出 ErrorEntryFreeException 异常。
注意 Sentinel 的降级仅针对业务异常,对 Sentinel 限流降级本身的异常 BlockException 不生效。为了统计异常比例或异常数,需要手动通过 Tracer.trace(ex) 记录业务异常。示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Entry entry = null; try { entry = SphU.entry(resource); // Write your biz code here. // <<BIZ CODE>> } catch (Throwable t) { if (!BlockException.isBlockException(t)) { Tracer.trace(t); } } finally { if (entry != null) { entry.exit(); } }
注意,通过 Tracer.trace(ex) 来统计异常信息时,由于 try-with-resources 语法中 catch 调用顺序的问题,会导致无法正确统计异常数,因此统计异常信息时也不能在 try-with-resources 的 catch 块中调用 Tracer.trace(ex)。
💡 为什么上一个需求中,我们不用手动调用 Tracer 上报异常呢?因为使用 Sentinel 的开源整合模块,如 Sentinel Dubbo Adapter, Sentinel Web Servlet Filter 或 @SentinelResource 注解会自动统计业务异常,无需手动调用。
需要给我们的资源定义增加异常统计代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 catch (Throwable ex) { // 业务异常 if (!BlockException.isBlockException(ex)) { Tracer.trace(ex); return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统错误"); } // 降级操作 if (ex instanceof DegradeException) { return handleFallback(questionQueryRequest, request, ex); } // 限流操作 return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "访问过于频繁,请稍后再试"); }
2)编写阻塞和降级操作代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 try { entry = SphU.entry("listQuestionVOByPage", EntryType.IN, 1, remoteAddr); // 被保护的业务逻辑 // 查询数据库 Page<Question> questionPage = questionService.listQuestionByPage(questionQueryRequest); // 获取封装类 return ResultUtils.success(questionService.getQuestionVOPage(questionPage, request)); } catch (Throwable ex) { // 业务异常 if (!BlockException.isBlockException(ex)) { Tracer.trace(ex); return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "系统错误"); } // 降级操作 if (ex instanceof DegradeException) { return handleFallback(questionQueryRequest, request, ex); } // 限流操作 return ResultUtils.error(ErrorCode.SYSTEM_ERROR, "访问过于频繁,请稍后再试"); } finally { if (entry != null) { entry.exit(1, remoteAddr); } } /** * listQuestionVOByPage 降级操作:直接返回本地数据 */ public BaseResponse<Page<QuestionVO>> handleFallback(QuestionQueryRequest questionQueryRequest, HttpServletRequest request, Throwable ex) { // 可以返回本地数据或空数据 return ResultUtils.success(null); }
3)通过编码方式定义规则。可以新建 sentinel 包并定义一个单独的 Manager 作为 Bean,利用 @PostConstruct 注解,在 Bean 加载后创建规则。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 @Component public class SentinelRulesManager { @PostConstruct public void initRules() { initFlowRules(); initDegradeRules(); } // 限流规则 public void initFlowRules() { // 单 IP 查看题目列表限流规则 ParamFlowRule rule = new ParamFlowRule("listQuestionVOByPage") .setParamIdx(0) // 对第 0 个参数限流,即 IP 地址 .setCount(60) // 每分钟最多 60 次 .setDurationInSec(60); // 规则的统计周期为 60 秒 ParamFlowRuleManager.loadRules(Collections.singletonList(rule)); } // 降级规则 public void initDegradeRules() { // 单 IP 查看题目列表熔断规则 DegradeRule slowCallRule = new DegradeRule("listQuestionVOByPage") .setGrade(CircuitBreakerStrategy.SLOW_REQUEST_RATIO.getType()) .setCount(0.2) // 慢调用比例大于 20% .setTimeWindow(60) // 熔断持续时间 60 秒 .setStatIntervalMs(30 * 1000) // 统计时长 30 秒 .setMinRequestAmount(10) // 最小请求数 .setSlowRatioThreshold(3); // 响应时间超过 3 秒 DegradeRule errorRateRule = new DegradeRule("listQuestionVOByPage") .setGrade(CircuitBreakerStrategy.ERROR_RATIO.getType()) .setCount(0.1) // 异常率大于 10% .setTimeWindow(60) // 熔断持续时间 60 秒 .setStatIntervalMs(30 * 1000) // 统计时长 30 秒 .setMinRequestAmount(10); // 最小请求数 // 加载规则 DegradeRuleManager.loadRules(Arrays.asList(slowCallRule, errorRateRule)); } }
4)测试
启动项目就能看到规则:
为了测试方便,可以先将规则的阈值调整小一点,然后通过接口文档验证效果。
限流效果:
测试降级效果的时候,可以故意将 sortField 传一个不存在的字段。效果如图,触发了 DegradeException:
Sentinel 的 熔断器恢复时是出于半开状态的,如果刚解除封印会根据第一次请求是否异常来判断是否开闭,如果无异常就恢复,否则继续出于关的状态。
扩展知识 1、仅对部分 URL 进行统计(性能优化) 参考:https://github.com/alibaba/spring-cloud-alibaba/wiki/Sentinel#%E9%85%8D%E7%BD%AE ‘
可以修改监听的 URL 规则配置:
1 spring.cloud.sentinel.filter.url-patterns=/*
2、规则配置本地持久化 参考官方文档的配置:https://sentinelguard.io/zh-cn/docs/dynamic-rule-configuration.html
官方提供了 Demo,可以用文件来本地持久化配置,这样重启项目后配置就不会丢失了。
示例代码如下,可以在 SentinelManager 的初始化逻辑中调用:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 /** * 持久化配置为本地文件 */ public void listenRules() throws Exception { // 获取项目根目录 String rootPath = System.getProperty("user.dir"); // sentinel 目录路径 File sentinelDir = new File(rootPath, "sentinel"); // 目录不存在则创建 if (!FileUtil.exist(sentinelDir)) { FileUtil.mkdir(sentinelDir); } // 规则文件路径 String flowRulePath = new File(sentinelDir, "FlowRule.json").getAbsolutePath(); String degradeRulePath = new File(sentinelDir, "DegradeRule.json").getAbsolutePath(); // Data source for FlowRule ReadableDataSource<String, List<FlowRule>> flowRuleDataSource = new FileRefreshableDataSource<>(flowRulePath, flowRuleListParser); // Register to flow rule manager. FlowRuleManager.register2Property(flowRuleDataSource.getProperty()); WritableDataSource<List<FlowRule>> flowWds = new FileWritableDataSource<>(flowRulePath, this::encodeJson); // Register to writable data source registry so that rules can be updated to file WritableDataSourceRegistry.registerFlowDataSource(flowWds); // Data source for DegradeRule FileRefreshableDataSource<List<DegradeRule>> degradeRuleDataSource = new FileRefreshableDataSource<>( degradeRulePath, degradeRuleListParser); DegradeRuleManager.register2Property(degradeRuleDataSource.getProperty()); WritableDataSource<List<DegradeRule>> degradeWds = new FileWritableDataSource<>(degradeRulePath, this::encodeJson); // Register to writable data source registry so that rules can be updated to file WritableDataSourceRegistry.registerDegradeDataSource(degradeWds); } private Converter<String, List<FlowRule>> flowRuleListParser = source -> JSON.parseObject(source, new TypeReference<List<FlowRule>>() { }); private Converter<String, List<DegradeRule>> degradeRuleListParser = source -> JSON.parseObject(source, new TypeReference<List<DegradeRule>>() { }); private <T> String encodeJson(T t) { return JSON.toJSONString(t); }
然后可以测试读写效果。
3、代码组织结构优化 限流阻塞和降级方法可以单独抽成独立的类,Sentinel 的资源名称也可以单独定义为常量,统一放到 sentinel 包中,更模块化。
常量类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /** * Sentinel 限流熔断常量 */ public interface SentinelConstant { /** * 分页获取题库列表接口限流 */ String listQuestionBankVOByPage = "listQuestionBankVOByPage"; /** * 分页获取题目列表接口限流 */ String listQuestionVOByPage = "listQuestionVOByPage"; }
4、封装限流组件为 Spring Boot Starter 为了简化项目的配置和依赖管理,减少限流组件的接入成本,我们通过 Starter 封装限流组件,将多个相关的依赖打包成一个 Maven 依赖,用户只需引入一个依赖即可完成配置,而不需要手动引入每个模块的依赖。
1)创建一个 spring boot 项目
将无用的默认依赖都移除,例如默认的配置文件、启动文件、test 相关等。
2)引入需要的依赖。完整 pom 文件如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 xml复制代码<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.7.2</version> <relativePath/> <!-- lookup parent from repository --> </parent> <groupId>com.yupi</groupId> <artifactId>limit-spring-boot-starter</artifactId> <version>0.0.1-SNAPSHOT</version> <name>limit-spring-boot-starter</name> <description>limit-spring-boot-starter</description> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-core</artifactId> <version>1.8.6</version> </dependency> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-transport-simple-http</artifactId> <version>1.8.6</version> </dependency> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-annotation-aspectj</artifactId> <version>1.8.6</version> </dependency> <dependency> <groupId>com.alibaba.csp</groupId> <artifactId>sentinel-parameter-flow-control</artifactId> <version>1.8.6</version> </dependency> </dependencies> </project>
3)创建配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 java复制代码@ConfigurationProperties(prefix = "spring") public class LimitProperties { private String sentinelDashboard; private List<LimitRule> limitRules; public List<LimitRule> getLimitRules() { return limitRules; } public void setLimitRules(List<LimitRule> limitRules) { this.limitRules = limitRules; } public String getSentinelDashboard() { return sentinelDashboard; } public void setSentinelDashboard(String sentinelDashboard) { this.sentinelDashboard = sentinelDashboard; } public static class LimitRule { private String resource; private int grade; private int count; public String getResource() { return resource; } public void setResource(String resource) { this.resource = resource; } public int getGrade() { return grade; } public void setGrade(int grade) { this.grade = grade; } public int getCount() { return count; } public void setCount(int count) { this.count = count; } } }
4)创建自动配置类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 java复制代码@Configuration @EnableConfigurationProperties(LimitProperties.class) public class LimitAutoConfiguration { @Resource private LimitProperties properties; @Bean @ConditionalOnMissingBean public SentinelResourceAspect sentinelResourceAspect () { return new SentinelResourceAspect (); } @PostConstruct public void initLimit () { initDefaultRule(); initDashboard(); } private void initDefaultRule () { List<LimitProperties.LimitRule> limitRules = properties.getLimitRules(); if (CollectionUtils.isEmpty(limitRules)) { return ; } List<FlowRule> rules = new ArrayList <>(); for (LimitProperties.LimitRule limitRule : limitRules) { FlowRule rule = new FlowRule (); rule.setResource(limitRule.getResource()); rule.setGrade(limitRule.getGrade()); rule.setCount(limitRule.getCount()); rules.add(rule); } FlowRuleManager.loadRules(rules); } private void initDashboard () { SentinelConfig.setConfig("csp.sentinel.dashboard.server" , properties.getSentinelDashboard()); } }
5)创建 spring.factories 文件。
在 src/main/resources/META-INF 目录下创建 spring.factories 文件,并在其中定义自动配置类。
文件内容:
1 2 plain复制代码org.springframework.boot.autoconfigure.EnableAutoConfiguration=\ com.yupi.limitspringbootstarter.LimitAutoConfiguration
6)本地 install
这样本地仓库就有了当前的 starter。
7)使用。后端项目引入此 starter:
1 2 3 4 5 xml复制代码 <dependency> <artifactId>limit-spring-boot-starter</artifactId> <groupId>com.yupi</groupId> <version>0.0.1-SNAPSHOT</version> </dependency>
application.yml 文件中填写对应限流配置:
1 2 3 4 5 6 7 8 yaml复制代码spring: # sentinel 控制台地址 sentinelDashboard: localhost:7878 # 限流规则 limitRules: - resource: "QuestionBank" count: 5 grade: 1
项目中同样还是使用 @SentinelResource注解,也可以通过控制台动态配置限流。
自主扩展 1)自主实现 push 规则推送模式,定义自己的持久化规则
参考文档:
2)自主实现更多限流功能,比如本文需求分析部分提到的用户登录和用户注册的保护
动态 IP 黑名单过滤 需求分析 一些恶意用户(可能是黑客、爬虫、DDoS 攻击者)可能频繁请求服务器资源,导致资源占用过高。因此我们需要一定的手段实时阻止可疑或恶意的用户,减少攻击风险。
通过 IP 封禁,可以有效拉黑攻击者,防止资源被滥用,保障合法用户的正常访问。
对于我们的需求,不让拉进黑名单的 IP 访问任何接口。
方案设计 1、设计过程 其实前面讲到的 Sentinel 本身就支持请求来源的 黑白名单判断 ,但默认是对应用级别进行判断,需要改造来源的获取方式为获取请求客户端的 IP,可参考 这篇文章 自定义来源。
但其实引入 Sentinel 是需要一定成本的,本节主要分享更轻量的动态 IP 黑白名单过滤的常用设计和实现方法。
想要自主实现动态 IP 黑名单,主要考虑以下几点:
IP 黑名单存储在哪里?
如何便捷地动态修改 IP 黑名单?
黑白名单的判断逻辑应在哪里处理?
使用何种数据结构保存黑名单?如何快速匹配用户请求的 IP 是否在黑名单中?
下面分别设计:
1)IP 黑名单存储在哪里?
最简单的方式就是存储在内存中,但一般 IP 黑名单是动态增加的、需要持久化保存。常见的持久化方式包括数据库、配置文件或分布式存储系统(如 Redis),可以根据需要选择。
2)如何便捷地动态修改 IP 黑名单?
为了方便动态修改 IP 黑名单,通常会提供一个管理页面,供管理员进行增删改查操作。
许多企业会将配置统一放入 配置中心 ,通过配置中心的管理页面,开发人员可以便捷地动态修改黑名单规则。Java 项目中,常用的配置中心是 Nacos。
3)黑白名单的判断逻辑应在哪里处理?
黑白名单逻辑通常部署在高性能的网关或 CDN 上,能够更早地拦截非法请求 ,减轻后端压力。在小型项目中,也可以直接在应用程序的过滤器中处理。
4)使用何种结构保存黑名单?如何快速匹配?
为了高效判断每个用户请求的 IP 是否在黑名单中,首先建议将 IP 黑名单从持久化存储同步到本地缓存中,避免频繁查询远程数据源。对于黑名单数据较小的场景,可以使用简单的 Set 数据结构存储。而对于大规模黑名单,推荐使用 布隆过滤器或 DFA 来存储和过滤黑名单,可以节约内存空间、提高检测效率。
2、最终方案 总结一下最终方案:
1)使用 Nacos 配置中心存储和管理 IP 黑名单
2)后端服务利用 Web 过滤器判断每个用户请求的 IP
3)后端服务利用布隆过滤器过滤 IP 黑名单
3、扩展知识 - 布隆过滤器 Bloom Filter 是一种高效的、基于概率的数据结构,用于判断一个元素是否存在于集合中。
原理是利用多个哈希函数将元素映射到固定的点位上(位数组中),因此面对海量数据它占据的空间也非常小。
例如某个 key 通过 hash-1 和 hash-2 两个哈希函数,定位到数组中的值都为 1,则说明它存在。
如果布隆过滤器判断一个元素不存在集合中,那么这个元素一定不在集合中,如果判断元素存在集合中则不一定是真的,因为哈希可能会存在冲突。因此布隆过滤器 有误判的概率 。
而且它不好删除元素,只能新增,如果想要删除,只能重建。
显然,它的主要特点包括:
空间效率高:相比于传统的数据结构(如哈希表),Bloom Filter 能用较少的空间存储大量的数据。
时间复杂度低:查询操作非常快速,通常是常数时间复杂度 O(1)。
允许误判:Bloom Filter 允许假阳性,即有时候会错误地判断某个元素在集合中,而实际该元素并不在集合中。不过,它不允许假阴性,也就是说,如果 Bloom Filter 判断某个元素不存在,那么它一定是不存在的。比如对于我们的需求,Bloom Filter 可能错误地判断一个不在黑名单中的元素为在黑名单中 ,导致误封。
Bloom Filter 的误判率与以下因素有关:
位数组的大小:位数组越大,误判率越低,但空间开销会增大。(值会更离散)
哈希函数的个数:哈希函数越多,误判率越低,但计算成本会增加。(Hash 一次冲突,那我就多 Hash 几次,减少冲突概率)
元素数量:存入的元素越多,误判率会增加。
通过 合理设计位数组的大小和哈希函数的个数 ,可以控制 Bloom Filter 的误判率在一个可接受的范围内。例如,在很多实际场景中,可以将误判率控制在 1% 或更低。
假设场景 1:存储 1000 个元素,位数组大小为 10000 位,哈希函数数量为 7。误判率大约为 0.8%。
假设场景 2:存储 100000 个元素,位数组大小为 1,000,000 位,哈希函数数量为 7。误判率大约为 1%。
假设场景 3:存储 1,000,000 个元素,位数组大小为 10,000,000 位,哈希函数数量为 7。误判率大约为 1%。
如果误判的代价较高,但仍想使用 Bloom Filter,可以采取一些补救措施:
双层验证:在 Bloom Filter 判断元素在黑名单中后,进一步查验实际的黑名单(例如,查数据库中的黑名单详细记录)。
结合其他数据结构:可以使用 Bloom Filter 进行初步筛选,如果 Bloom Filter 判断为在黑名单中,再用哈希表等精确的数据结构进行最终确认。
但这两种方式都无法处理攻击 IP 的大量请求,个人也不建议采用。
因此,布隆过滤器适用于对准确性要求不高的、大规模数据量匹配的场景,比如垃圾邮件过滤、爬虫 URL 去重、缓存穿透防护等。


扩展知识:Redis 键设计规范 明确性:键名称应明确表示数据的含义和结构。例如,通过使用signins 可以清楚地知道这个键与用户的签到记录有关。 层次结构:使 号:分隔不同的部分,可以使键结构化,便于管理和查询。 唯一性:确保键的唯一性,避免不同数据使用相同的键前缀。 一致性:在整个系统中保持键设计的一致性,使得管理和维护变得更加简单。 长度:避免过长的键名称,以防影响性能和存储效率。